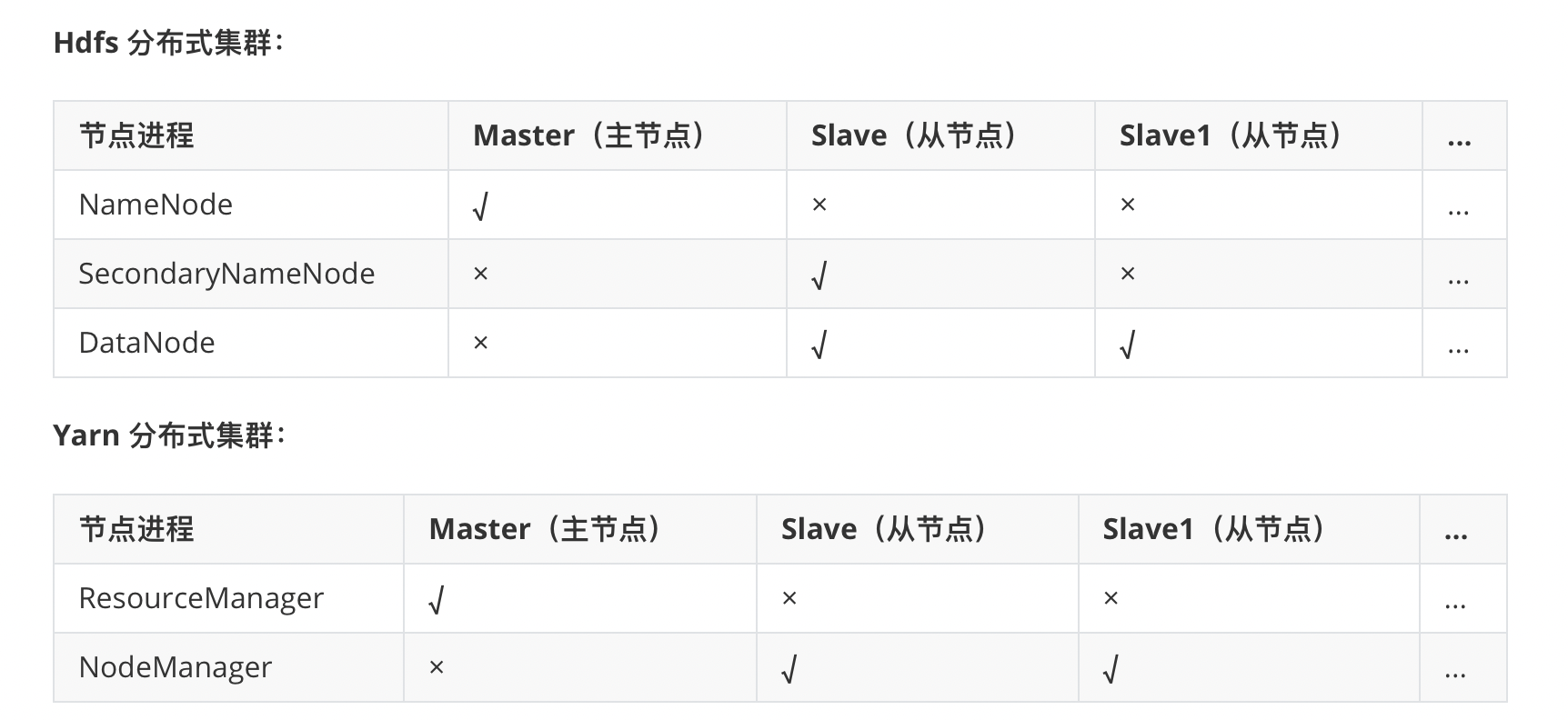
2.4 集群规划

core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置,用户自定义配置会覆盖系统配置
以下内容所有节点操作基本一致(换言之,主节点配置完成可以把配置拷贝到从节点);
准备至少两台 Ubuntu 计算机(可以是虚拟机)
确保机器之间网络是通的,并且保证每台机器都装有 SSH 服务
安装 SSH 服务命令:
查询出每台计算机的 Ip 并确定机器名
查看 Ip 的命令:
ip a
给定 ip 和机器名列表,如下:

让 /etc/hostname 和 /etc/hosts 文件修改内容生效
sudo hostname -F /etc/hostname
或
sudo reboot
sudo useradd -m -d /home/briup -u 20000 -s /bin/bash briup
sudo passwd briup
将 briup 用户添加到 sudo 组,设置 briup 账号密码
sudo usermod -G sudo briupsudo passwd briupsu - briup10.把软件 jdk-8u91-linux-x64.tar.gz、hadoop-3.1.3.tar.gz 复制到搭建集群用户的家目录下scp hadoop-3.1.3.tar.gz briup@192.168.174.136:~scp jdk-8u91-linux-x64.tar.gz briup@192.168.174.136:~scp hadoop-3.1.3.tar.gz briup@192.168.174.137:~scp jdk-8u91-linux-x64.tar.gz briup@192.168.174.137:~11.在 briup 家目录中创建 software 目录mkdir software 12.解压软件 jdk-8u91-linux-x64.tar.gz、hadoop-3.1.3.tar.gz 到 briup 家目录 software 中
tar -zxvf hadoop-3.1.3.tar.gz -C ~/software
tar -zxvf jdk-8u91-linux-x64.tar.gz -C ~/software
13.构建软连接
cd /software
ln -s hadoop-3.1.3 hadoop
ln -s jdk1.8.0_91 jdk
修改 briup 用户下配置文件
配置文件内容如下:
export JAVA_HOME=/home/briup/software/jdk
export HADOOP_HOME=/home/briup/software/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

在 Hadoop 安装目录中创建日志记录文件 logs
进入 Hadoop 安装目录
cd ~/software/hadoop/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/home/briup/software/jdk
设置 Jdk 的加载路径
修改 hadoop-env.sh(hadoop的启动脚本)
加入内容如下:
注意:Hadoop 的启动脚本要求知道 Jdk 的安装在什么位置
原因:Hadoop 本身是由 Java 开发的,54行
进入配置目录 ~/software/hadoop/etc/hadoop,修改 core-site.xml 文件
vi core-site.xml修改内容如下:指明在集群中谁承担主节点的角色
<configuration> <!--Hdfs集群的入口--> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- 配置HDFS网页登录使用的静态用户为 --> <property> <name>hadoop.http.staticuser.user</name> <value>briup</value> </property> <!-- 配置该briup(superUser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.briup.hosts</name> <value>*</value> </property> <!-- 配置该briup(superUser)允许通过代理用户所属组 --> <property> <name>hadoop.proxyuser.briup.groups</name> <value>*</value> </property> <!-- 配置该briup(superUser)允许通过代理的用户--> <property> <name>hadoop.proxyuser.briup.users</name> <value>*</value> </property></configuration>注意:
集群中的任何一个节点其实都可以充当客户端
默认规则:端口一般是 9000
18.进入配置目录 software/hadoop/etc/hadoop,修改 hdfs-site.xml 文件
修改内容如下:
<configuration>
<!--集群的名字-->
<property>
<name>dfs.nameservices</name>
<value>hadoop-master</value>
</property>
<!--数据块备份数,默认备份是3,备份数不能大于从节点的个数,可选配置-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设定SNN运行主机和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave:9868</value>
</property>
<!--主节点存储Hdfs文件系统中文件及目录的元数据-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/briup/software/data/hadoop/hdfs/nn</value>
</property>
<!--主节点存储检查相关日志数据-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/home/briup/software/data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/home/briup/software/data/hadoop/hdfs/snn</value>
</property>
<!--从节点存放hdfs文件系统中的文件的数据,如需要指定多个数据目录,路径之间逗号隔开-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/briup/software/data/hadoop/hdfs/dn</value>
</property>
</configuration>
进入配置目录 software/hadoop/etc/hadoop,修改 mapred-site.xml 文件
<configuration>
vi yarn-site.xml
在 /home/briup/software/ 路径下创建 data 目录
进入 hadoop 目录cd /home/briup/software/data/hadoop或cd hadoop
在 hadoop 中建立 hdfs 和 yarn 文件夹
mkdir hdfs yarn
进入 hdfs 目录
cd /home/briup/software/data/hadoop/hdfs或cd hdfs
创建目录 dn、nn、snn
mkdir dn nn snn
进入hadoop下的yarn目录
cd /home/briup/software/data/hadoop/yarn
或
cd ../yarn
注意:
过程中提示是否继续格式化,Yes注意大小写,只格式化一次
从节点和主节点配置方式一样,除修改机器名字操作,并且从节点不需要修改配置文件workers
启动 hdfs 集群和 yarn 集群的操作命令
主节点上做的事
启动/关闭 hdfs 集群主节点
hadoop-daemon.sh start/stop namenode启动/关闭 yarn 集群主节点
yarn-daemon.sh start/stop resourcemanager从节点启动
启动/关闭 hdfs 集群从节点
hadoop-daemon.sh start/stop datanode 启动/关闭 yarn 集群从节点
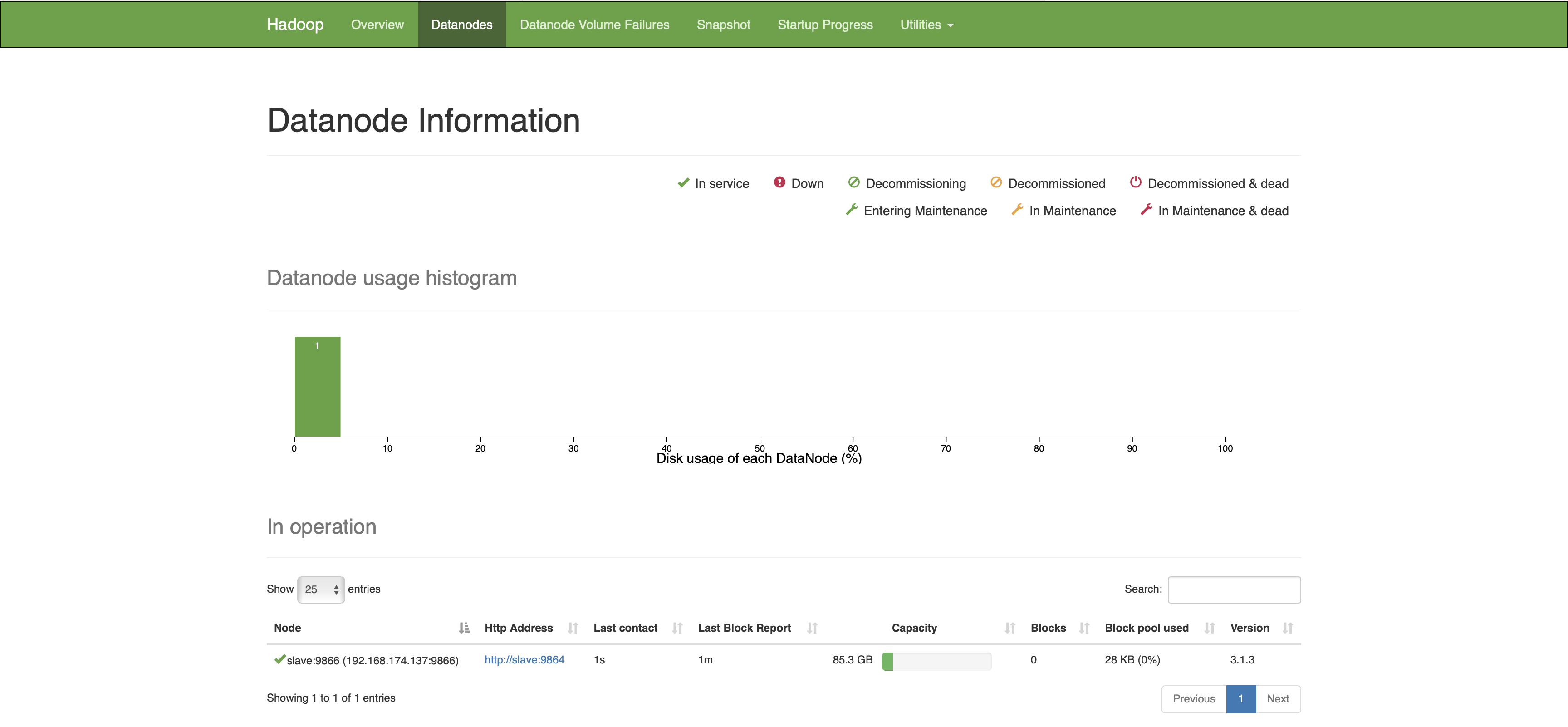
yarn-daemon.sh start/stop nodemanagerHdfs 集群网页查看
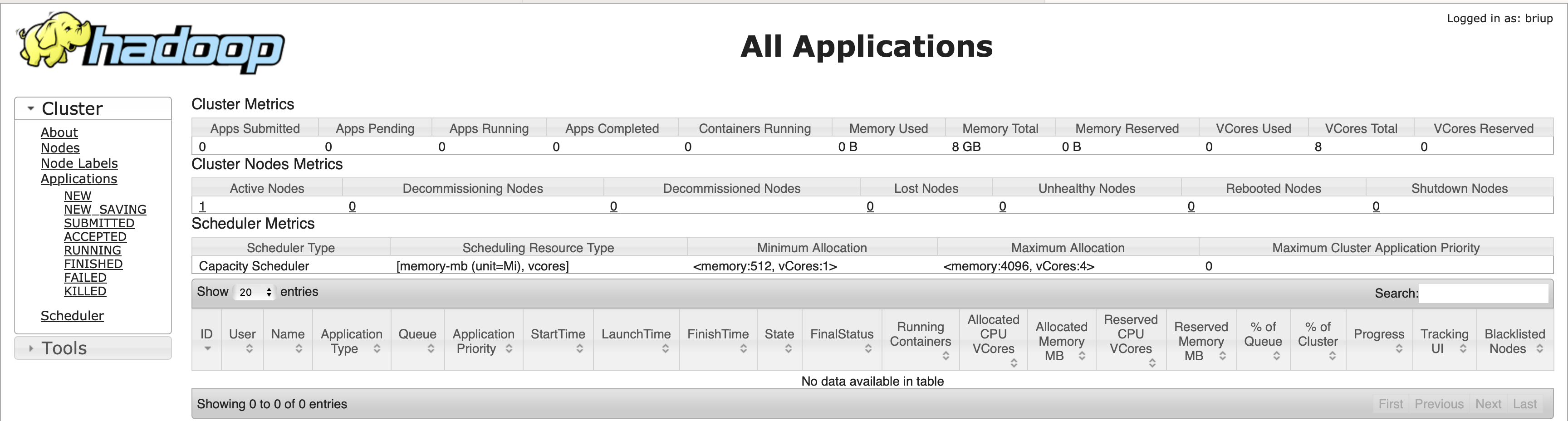
Yarn 集群网页查看
在主节点一个命令启动 Hdfs 和 Yarn 集群
前提:主从节点安装了 SSH 服务
主节点上的用户和从节点上的用户名字一致
解决无密码登陆的问题(dsa)
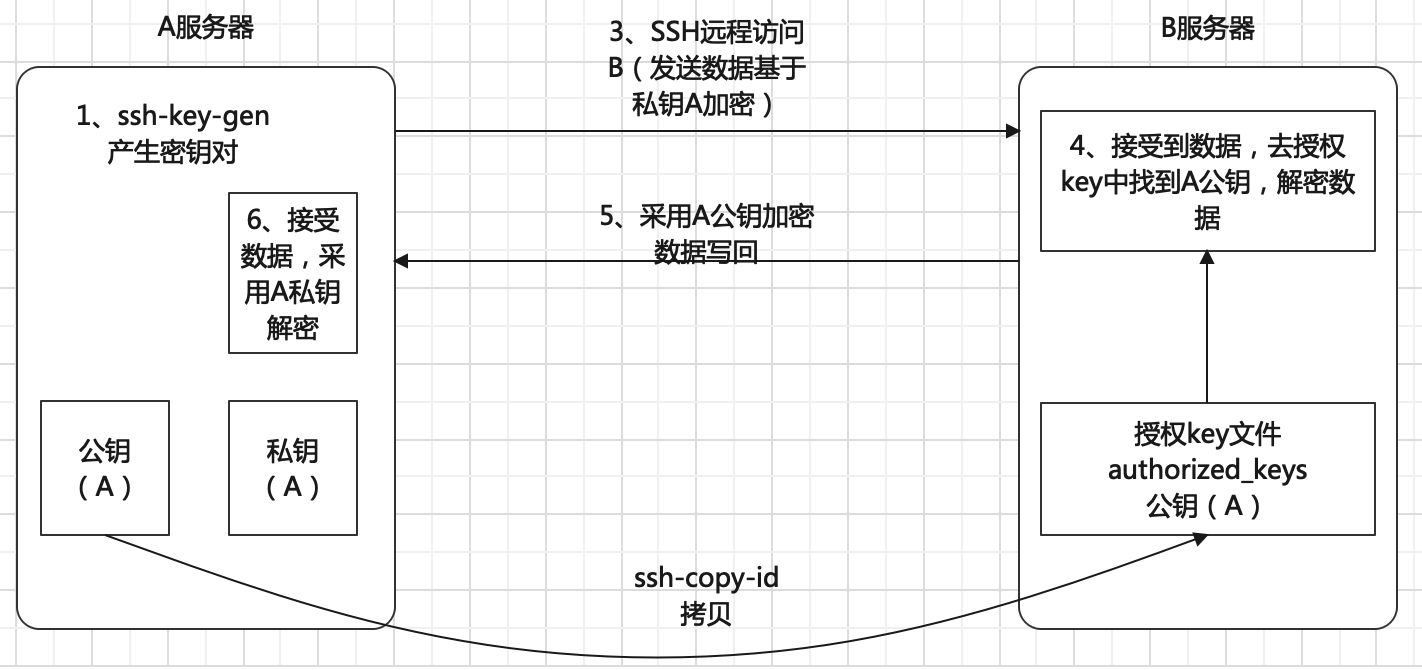
在主节点生成公钥和私钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa将公钥拷贝到需要无密码登陆的机器上去
ssh-copy-id -i 192.168.174.137注意:在主节点 briup 用户下,
ssh-copy-id -i localhost验证是否可以无密码登陆,在主节点操作如下:
ssh 192.168.174.137启动 Yarn 集群
start-yarn.sh关闭 Yarn 集群
stop-yarn.sh启动 Hdfs 集群
start-dfs.sh关闭 Hdfs 集群
stop-dfs.sh整个集群的启动
start-all.sh 整个集群的关闭
stop-all.shSecondarynamenode 节点启动
hadoop-daemon.sh start secondarynamenodesecondarynamenode 执行情况:
1、每隔一个小时执行一次
2、每隔一分钟检查一次操作次数,单操作次数达到1百万时,执行一次
3、该命令只在指定的计算机中执行
一般情况可以不配置(主节点负载过重,考虑配置)
配置 Windows 域名映射
以管理员身份打开 C:\Windows\System32\drivers\etc 目录下的 hosts 文件,在文件最后配置内容如下:
192.168.174.136 master
192.168.174.137 slavewindows下设置环节变量
HADOOP_USER_NAME=briup集群节点进程查看
在家目录 /home/briup/software 中创建目录bin目录
mkdir /home/briup/software/bin编辑查看进程脚本
vi jpsall脚本内容
#!/bin/bash
for host in master slave
do
echo =================$host=============
ssh $host '/home/briup/software/jdk/bin/jps'
done
赋予文件执行权限
chmod 777 jpsall配置环境变量
vi .bashrc 在.bashrc文件最后追加内容如下:export JAVA_HOME=/home/briup/software/jdk
export HADOOP_HOME=/home/briup/software/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:/home/briup/software/bin配置文件生效source .bashrc 测试jpsall


 苏ICP备2020067766号-2
苏ICP备2020067766号-2