3.4 节点作用
3.4.1 NameNode 作用
维护着文件系统中所有文件和目录的元数据
整个 HDFS 可存储的文件数受限于 NameNode 的内存大小
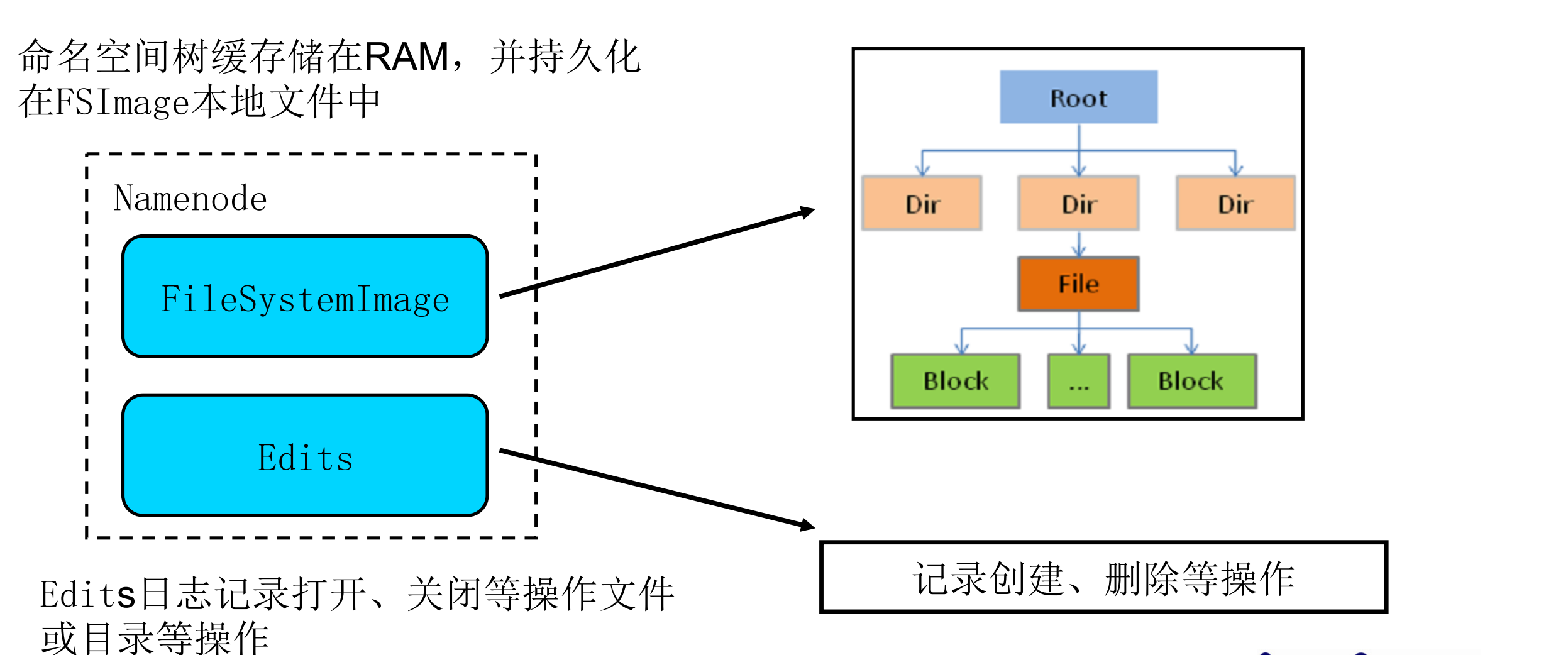
文件名、文件目录结构、文件属性(生成时间,副本数,权限)每个文件的块列表以及列表中的块与块所在的DataNode 之间的地址映射关系,在内存中加载文件系统中每个文件和每个数据块的引用关系(文件、block、DataNode 之间的映射信息) 数据会定期保存到本地磁盘(fsImage 文件和 edits 文件)。
协调客户端对文件的访问
NameNode 负责文件元数据的操作 ,DataNode 负责处理文件内容的读写请求,数据流不经过 NameNode,会询问它跟那个 DataNode 联系。
文件数据块到底存放到哪些 DataNode 上,是由 NameNode 决定的,NN 根据全局情况做出放置副本的决定 。
全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该 DataNode 上所有数据块的列表) 若接收到心跳信息,NameNode 认为 DataNode 工作正常,如果在 10 分钟后还接受到不到 DataNode 的心跳,那么 NameNode 认为 DataNode 已经宕机 ,这时候 NN 准备要把 DataNode 上的数据块进行重新的复制。 块的状态报告包含了一个 DataNode 上所有数据块的列表,blocks report 每个 1 小时发送一次.。
3.4.2 DataNode 作用
提供真实文件数据的存储服务。
DataNode 以数据块的形式存储 HDFS 文件
DataNode 响应 HDFS 客户端读写请求
DataNode 周期性向 NameNode 汇报心跳信息
DataNode 周期性向 NameNode 汇报数据块信息
DataNode 周期性向 NameNode 汇报缓存数据块信息
数据块汇报,相关hdfs-site.xml配置如下:
DN向NN汇报当前解读信息的时间间隔,默认6小时;
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
namenode中没有维护元数据,数据块在从节点存在,多余的数据块在汇报之后也会被删除
- DN扫描自己节点块信息列表的时间,默认6小时
- <property>
- <name>dfs.datanode.directoryscan.interval</name>
- <value>21600s</value>
- <description>Interval in seconds for Datanode to scan data directories and reconcile the difference between blocks in memory and on the disk.
- Support multiple time unit suffix(case insensitive), as described
- in dfs.heartbeat.interval.
- </description>
- </property>
当 HDFS 集群运行一段事件后,就会出现下面一些问题:
edits logs 会变的很大,fsimage 将会变得很旧;
NameNode 重启会花费很长时间,因为有很多改动要合并到 fsimage 文件上;
如果频繁进行 fsimage 持久化,又会影响 NameNode 正常服务,毕竟 IO 操作是一种内存到磁盘的耗精力操作。
因此为了克服以上问题,需要一个易于管理的机制来帮助我们减小 edit logs 文件的大小和得到一个最新的 fsimage文件,这样也会减小在 NameNode 上的压力,SecondaryNameNode 就是来帮助解决上述问题的,它的职责是合并NameNode的 edit logs 到 fsimage 文件中。
SecondaryNameNode 会在满足条件的时候将 NameNode 的 fsimage 和 edits 文件拷贝到所在主机合并,合并触发条件配置在 hdfs-site.xml 文件,内容如下:
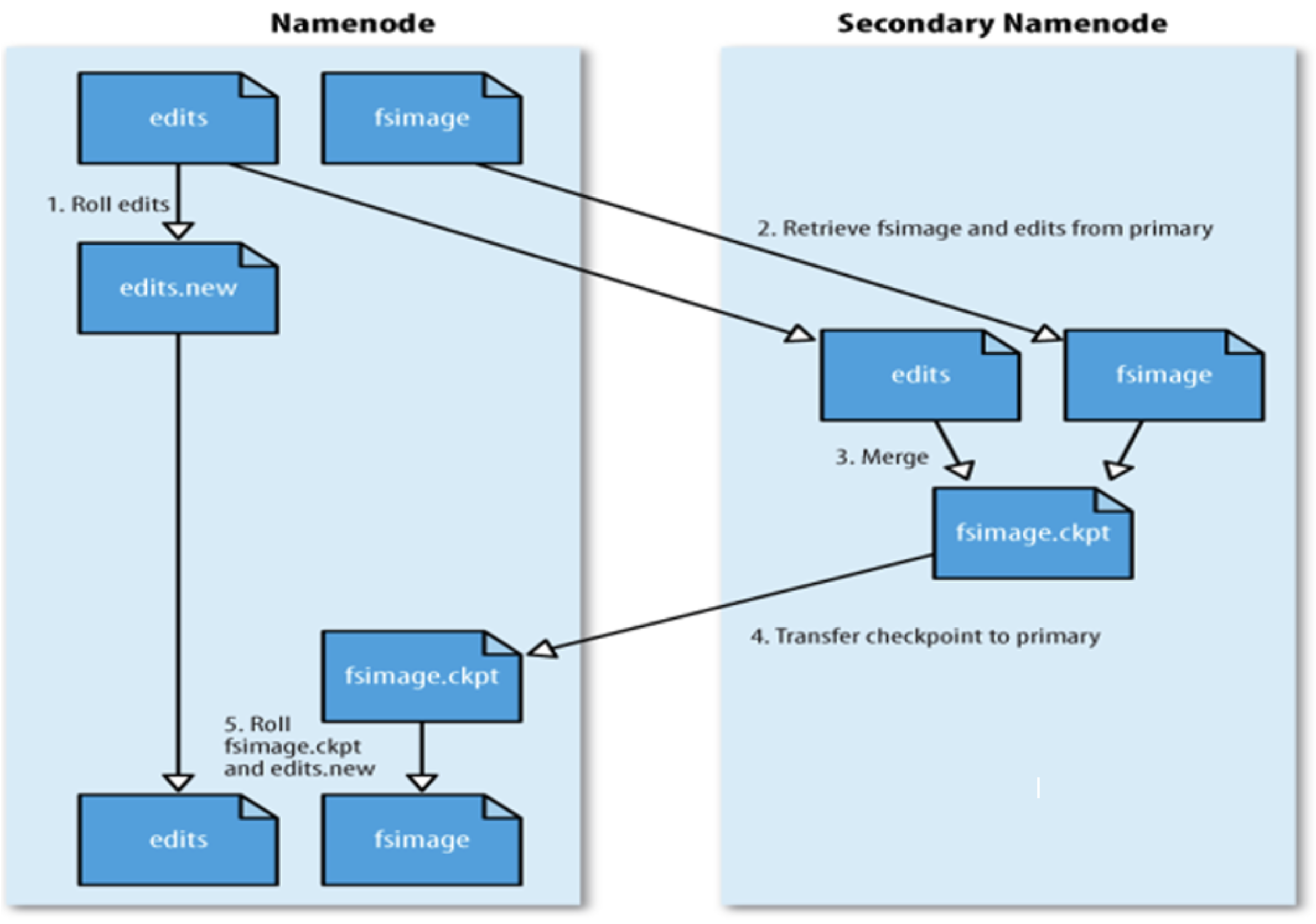
1、触发 checkpoint 操作条件时,SNN 发生请求给 NameNode 滚动 edits log。然后 NameNode 会生成一个新的编辑日志文件:edits new,便于记录后续操作记录。
2、同时 SecondaryNameNode 会将 edits 文件和 fsimage 复制到本地(使用 HTTP GET 方式)。
3、SecondaryNameNode 首先将 fsimage 载入到内存,然后一条一条地执行 edits 文件中的操作,使得内存中的fsimage 不断更新,这个过程就是 edits 和 fsimage 文件合并。合并结束,SecondaryNameNode 将内存中的数据dump 生成一个新的 fsimage 文件。
3、 SecondaryNameNode 将新生成的 Fsimage new 文件复制到 NameNode 节点。
4、至此刚好是一个轮回,等待下一次 checkpoint 触发 SecondaryNameNode 进行工作,一直这样循环操作。
SNN 了解即可,一般企业级开发会搭建高可用的 Hadoop 集群


 苏ICP备2020067766号-2
苏ICP备2020067766号-2