3.12 Archive 归档
HDFS 并不擅长存储小文件,因为每个文件最少一个 block,每个 block 的元数据都会在 NameNode 占用内存,如果存在大量的小文件,它们会吃掉 NameNode 节点的大量内存。
Hadoop Archives 可以有效的处理以上问题,它可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件。
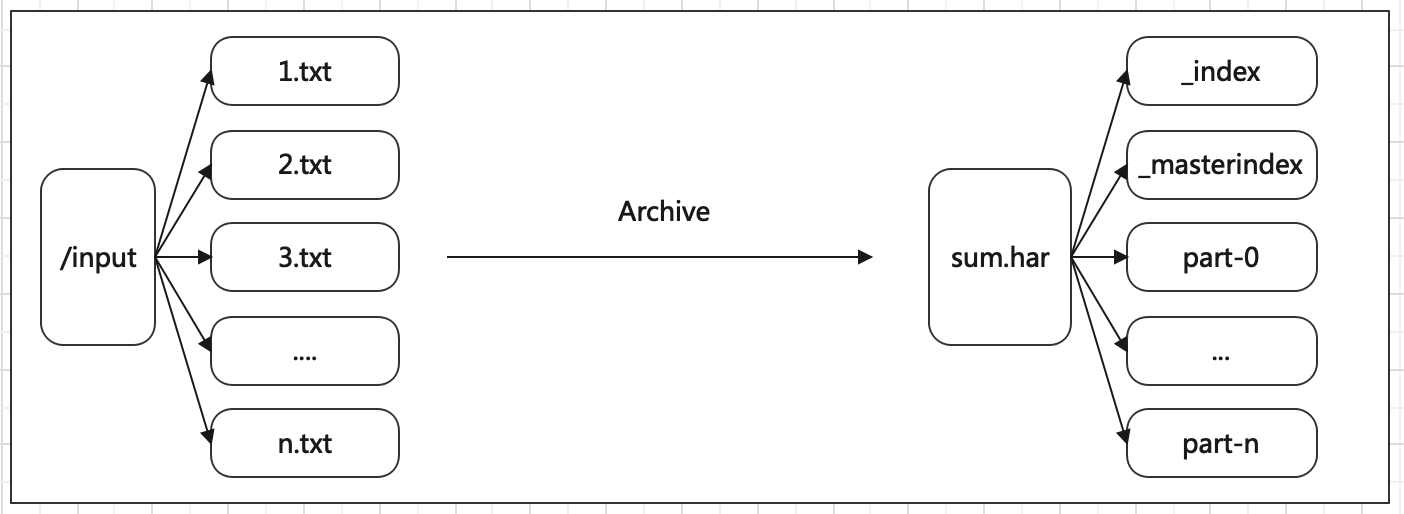
数据准备:
1、创建目录
hdfs dfs -mkdir /input2、在本机创建多个文件
vi 1.txt
vi 2.txt
vi 3.txt
vi 4.txt
1.txt内容如下:
12.txt内容如下:
23.txt内容如下:
34.txt内容如下:
45、将1.txt、2.txt、3.txt、4.txt文件上传到集群/input目录下
hdfs dfs -put *.txt /inputArchive创建:
语法:hadoop archive -archiveName name -p <parent> <src>* <dest>
-archiveName 是指要创建的存档的名称。比如 test.har,archive 的名字的扩展名应该是 *.har
-p 参数指定文件存档文件(src)的相对路径
案例1:将 /input 路径下的所有小文件归档
hadoop archive -archiveName test.har -p /input /output归档文件查看:Archive 归档是通过 MapReduce 程序完成的,需要启动 Yarn 集群
语法:
hadoop fs -ls path案例1:查看归档文件
hadoop fs -ls /output/test.har
test.har 文件包括:两个索引文件,多个 part 文件(本例只有一个)以及一个标识成功与否的文件。part 文件是多个原文件的集合, 通过 index 文件可以去找到原文件。
案例2:查看归档中数据汇总文件
hadoop fs -cat /output/test.har/part-0
归档协议访问:
在查看 har 文件的时候,如果没有指定访问协议,默认使用的就是 hdfs://,此时所能看到的就是归档之后的样子。Archive 还提供了自己的 har uri 访问协议。如果用 har uri 去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
Hadoop Archives 的 URI 是:
har://scheme-hostname:port/archivepath/fileinarchive scheme-hostname格式为hdfs-域名:端口
hadoop fs -ls har://hdfs-192.168.174.136:9000/output/test.har/
或
hadoop fs -ls har:///output/test.har/

案例2:查看归档下的具体某个文件
hadoop fs -cat har:///output/test.har/1.txt
归档提取:
案例1:按顺序解压存档(串行)
hadoop fs -cp har:///output/test.har/* hdfs:/user/briup案例2:并行解压存档,使用DistCp,对应大的归档文件可以提高效率
hadoop distcp har:///output/test.har/* hdfs:/user/briup归档注意事项:
Hadoop archives 是特殊的档案格式。一个 Hadoop archive 对应一个文件系统目录。Hadoop archive 的扩展名是 *.har
创建 archives 本质是运行一个 Map/Reduce 任务,所以应该在 Hadoop 集群上运行创建档案的命令
创建 archive 文件要消耗和原文件一样多的硬盘空间
archive 文件不支持压缩,尽管 archive 文件看起来像已经被压缩过
archive 文件一旦创建就无法改变,要修改的话,需要创建新的 archive 文件。事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日
当创建 archive 时,源文件不会被更改或删除


 苏ICP备2020067766号-2
苏ICP备2020067766号-2