4.6 案例
4.6.1 WordCount
统计每个单词出现的次数
创建一个新的文件
cd ~
vi word.txt
vi word1.txt文件word.txt
向其中放入以下内容并保存
hello,world,good,briup
byebye,hello,good,hello
文件word1.txt
world,briup,good
good,briup,byebye3.将文件上传到 HDFShdfs dfs -put word.txt word1.txt /user/hdfs/words注意:hdfs分布式文件系统集群中/user/hdfs目录必须先存在
目录不存在,创建目录命令如下:
hdfs dfs -mkdir -p /user/hdfs/words
原理分析
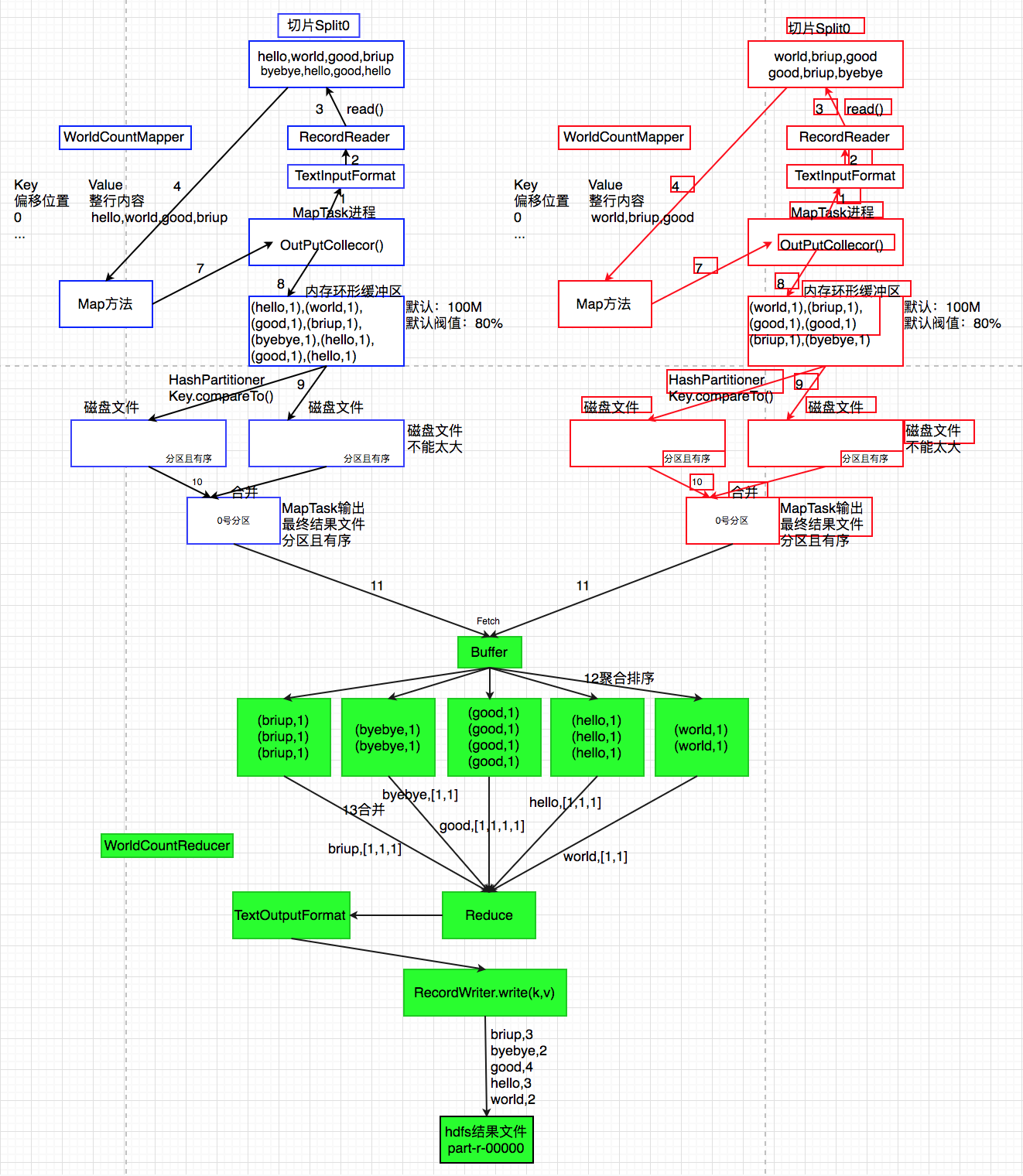
代码实现如下:
package com.briup.MR;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class WorldCount extends Configured implements Tool {
static class WorldCountMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] strs=value.toString().split(",");
for(String str:strs){
context.write(new Text(str),new IntWritable(1));
}
}
}
static class WorldCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
context.write(key,new IntWritable(sum));
}
}
public int run(String[] args) throws Exception {
//构建配置对象,读取hadoop的配置文件,如hdfs-site.xml、yarn-site.xml、
//core-site.xml、mapred-site.xml等
Configuration conf=getConf();
//指定需要处理数据的hdfs文件路径
String input=conf.get("input");
//指定Mapreduce程序执行结果存放的路径
String output=conf.get("output");
//构建作业程序
Job job=Job.getInstance(conf);
//指定作业运行的类
job.setJarByClass(this.getClass());
//指定提交作业的名字
job.setJobName("WorldCount");
//指定Mapper程序是哪个类
job.setMapperClass(WorldCountMapper.class);
//指定Mapper输出的键类型
job.setMapOutputKeyClass(Text.class);
//指定Mapper输出的值的类型
job.setMapOutputValueClass(IntWritable.class);
//设置Reduce的个数
job.setNumReduceTasks(1);
//指定Reduce程序是哪个类
job.setReducerClass(WorldCountReducer.class);
//指定Reduce程序输出的键类型
job.setOutputKeyClass(Text.class);
//指定Reduce程序输出值的类型
job.setOutputValueClass(IntWritable.class);
//指定文件和Mapper之间对接的处理器,处理器负责将文件每行内容按照特定规则转化为键值
//键值对交给Mapper
//TextInputFormat读取每一行数据起始位置为偏移位置,整行内容为值
job.setInputFormatClass(TextInputFormat.class);
//指定Reduce输出结果和结果存储文件的处理器,处理器负责将Reduce输出键值对按照特定规则写入结果文件
job.setOutputFormatClass(TextOutputFormat.class);
//负责读数据的处理器绑定读取文件路径
TextInputFormat.addInputPath(job,new Path(input));
//负责写数据的处理器绑定存储结果文件路径
TextOutputFormat.setOutputPath(job,new Path(output));
//提交作业给集群,true表示集群执行程序结束提交窗口命令行
return job.waitForCompletion(true)?0:-1;
}
public static void main(String[] args) throws Exception {
System.exit(
new ToolRunner().run(
new WorldCount(),args));
}
}
将编写的程序所在工程打成jar包

将项目jar包拷贝或拖拽到hadoop集群中,下面以从hadoo集群从项目jar包所在计算机命令拷贝测试
语法:sudo scp jar所在计算机用户名@jar所在计算机IP:jar包所在路径 集群中操作计算机jar包存放位置
sudo scp huzhongliang@192.168.43.158:/Users/huzhongliang/Documents/idea_work/t1_test/target/t1_test-1.0-SNAPSHOT.jar .提交程序给集群执行
yarn jar t1_test-1.0-SNAPSHOT.jar com.briup.MR.WorldCount -D input=/user/hdfs/words -D output=/user/hdfs/words_result注意:
服务器计算机必须安装openssh-server服务
如果jar包在windows计算机,windows必须支持scp命令
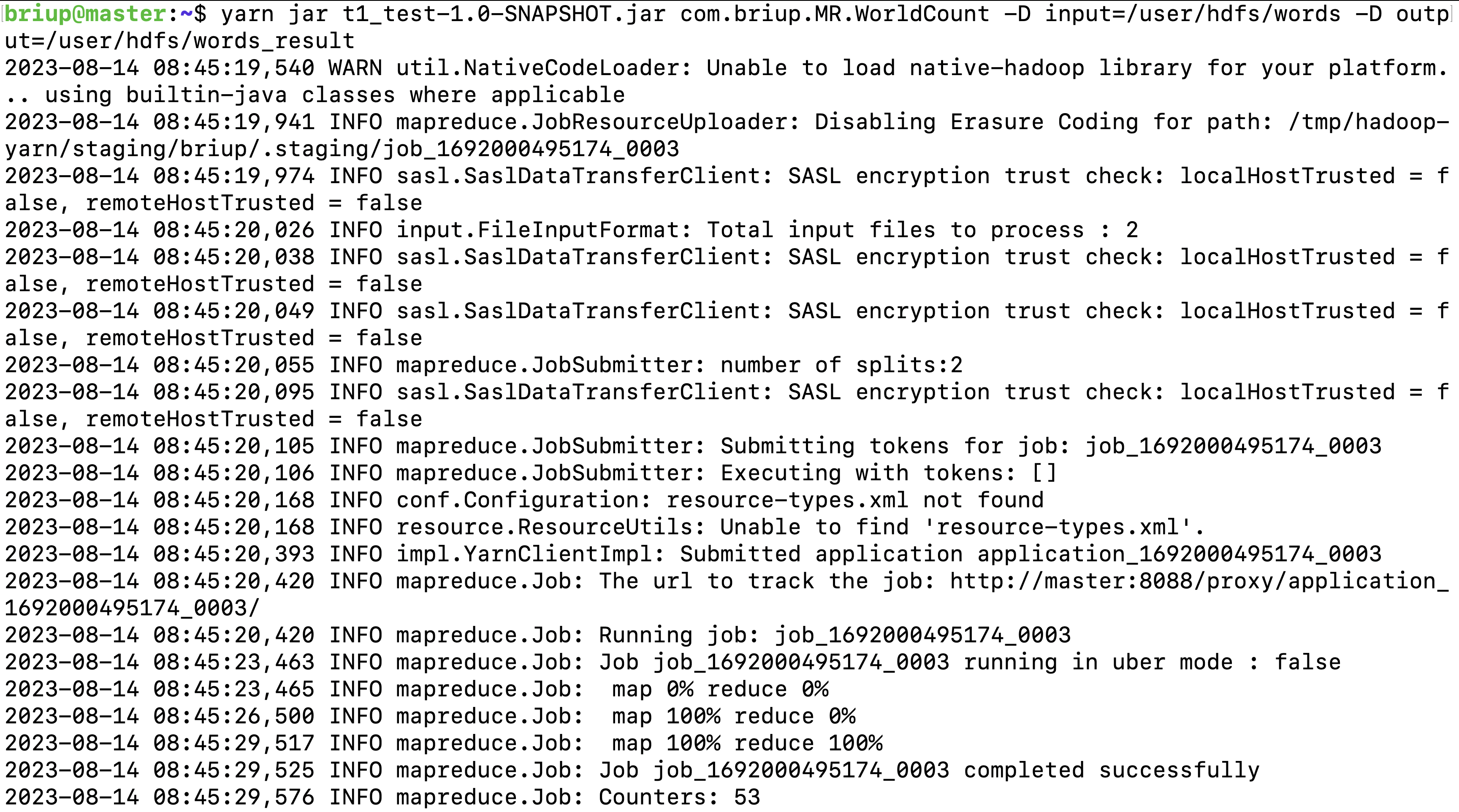

查看计算结果
hdfs dfs -cat /user/hdfs/words_result/part-r-00000*执行过程日志说明**
Hadoop为每个MapReduce作业维护一些内置的计数器,这些计数器报告各种指标,例如和MapReduce程序执行中每个阶段输入输出的数据量相关的计数器,可以帮助用户进行判断程序逻辑是否生效、正确。
Hadoop内置计数器根据功能进行分组。每个组包括若干个不同的计数器,分别是:MapReduce任务计数器(Map-Reduce Framework)、文件系统计数器(File System Counters)、作业计数器(Job Counters)、输入文件任务计数器(File Input Format Counters)、输出文件计数器(File Output Format Counters)。
需要注意的是,内置的计数器都是MapReduce程序中全局的计数器,跟MapReduce分布式运算没有关系,不是所谓的每个局部的统计信息。
File System Counters
文件系统的计数器会针对不同的文件系统使用情况进行统计,比如HDFS、本地文件系统.
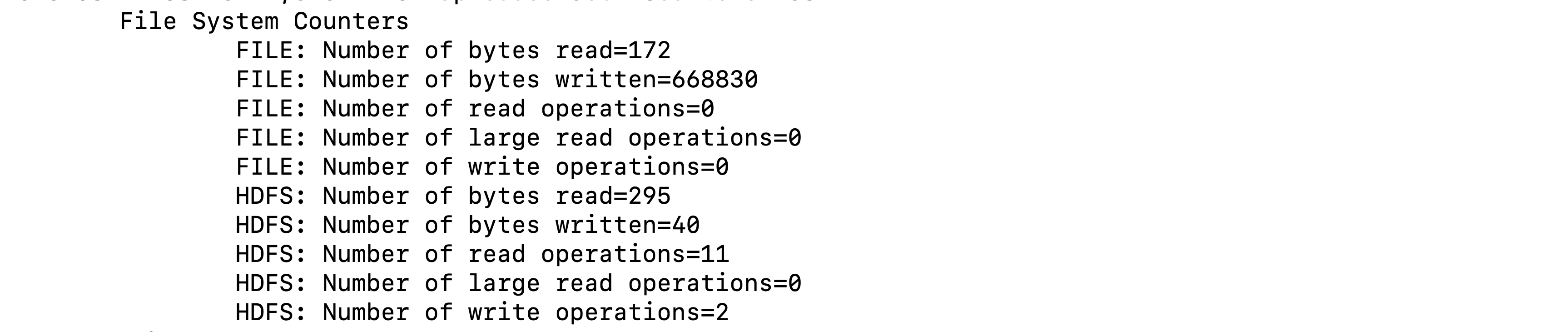
| 计数器名称 | 说明 |
|---|---|
| BYTES_READ | 程序从文件系统中读取的字节数 |
| BYTES_WRITTEN | 程序往文件系统中写入的字节数 |
| READ_OPS | 文件系统中进行的读操作的数量(例如,open操作,filestatus操作) |
| LARGE_READ_OPS | 文件系统中进行的大规模读操作的数量 |
| WRITE_OPS | 文件系统中进行的写操作的数量(例如,create操作,append操作) |
Job Counters作业计数器

| 计数器名称 | 说明 |
|---|---|
| Launched map tasks | 启动的map任务数,包括以“推测执行”方式启动的任务 |
| Launched reduce tasks | 启动的reduce任务数,包括以“推测执行”方式启动的任务 |
| Data-local map tasks | 与输人数据在同一节点上的map任务数 |
| Total time spent by all maps in occupied slots (ms) | 所有map任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all reduces in occupied slots (ms) | 所有reduce任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all map tasks (ms) | 所有map task花费的时间 |
| Total time spent by all reduce tasks (ms) | 所有reduce task花费的时间 |
Map-Reduce Framework
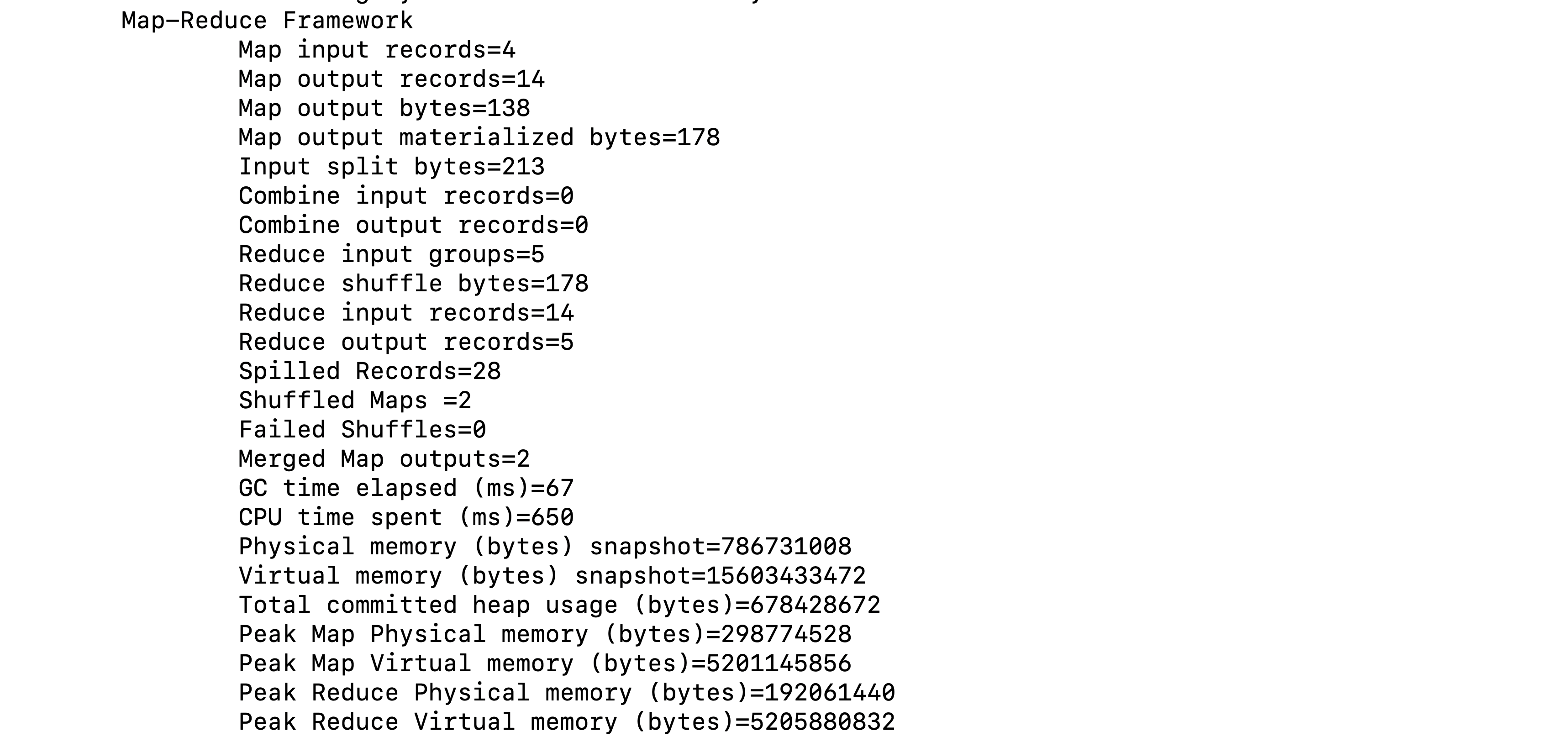
| 计数器名称 | 说明 |
|---|---|
| MAP_INPUT_RECORDS | 所有mapper已处理的输入记录数 |
| MAP_OUTPUT_RECORDS | 所有mapper产生的输出记录数 |
| MAP_OUTPUT_BYTES | 所有mapper产生的未经压缩的输出数据的字节数 |
| MAP_OUTPUT_MATERIALIZED_BYTES | mapper输出后确实写到磁盘上字节数 |
| COMBINE_INPUT_RECORDS | 所有combiner(如果有)已处理的输入记录数 |
| COMBINE_OUTPUT_RECORDS | 所有combiner(如果有)已产生的输出记录数 |
| REDUCE_INPUT_GROUPS | 所有reducer已处理分组的个数 |
| REDUCE_INPUT_RECORDS | 所有reducer已经处理的输入记录的个数。每当某个reducer的迭代器读一个值时,该计数器的值增加 |
| REDUCE_OUTPUT_RECORDS | 所有reducer输出记录数 |
| REDUCE_SHUFFLE_BYTES | Shuffle时复制到reducer的字节数 |
| SPILLED_RECORDS | 所有map和reduce任务溢出到磁盘的记录数 |
| CPU_MILLISECONDS | 一个任务的总CPU时间,以毫秒为单位,可由/proc/cpuinfo获取 |
| PHYSICAL_MEMORY_BYTES | 一个任务所用的物理内存,以字节数为单位,可由/proc/meminfo获取 |
| VIRTUAL_MEMORY_BYTES | 一个任务所用虚拟内存的字节数,由/proc/meminfo获取 |
File Input Format Counters

| 计数器名称 | 说明 |
|---|---|
| 读取的字节数(BYTES_READ) | 由map任务通过FilelnputFormat读取的字节数 |
File Output Format Counters

| 计数器名称 | 说明 |
|---|---|
| 写的字节数(BYTES_WRITTEN) | 由map任务(针对仅含map的作业)或者reduce任务通过FileOutputFormat写的字节数 |
4.6.2 每年最高温度
统计每年的最高温度
创建一个新的文件
cd ~
vi wea.txt
vi wea1.txt文件wea.txt
向其中放入以下内容并保存
2020,26
2017,34
2016,22
2017,30
2019,29
文件wea1.txt
2018,31
2016,36
2019,28
2020,29
将文件上传到 HDFS
hdfs dfs -put wea.txt wea1.txt /user/hdfs/wea原理分析
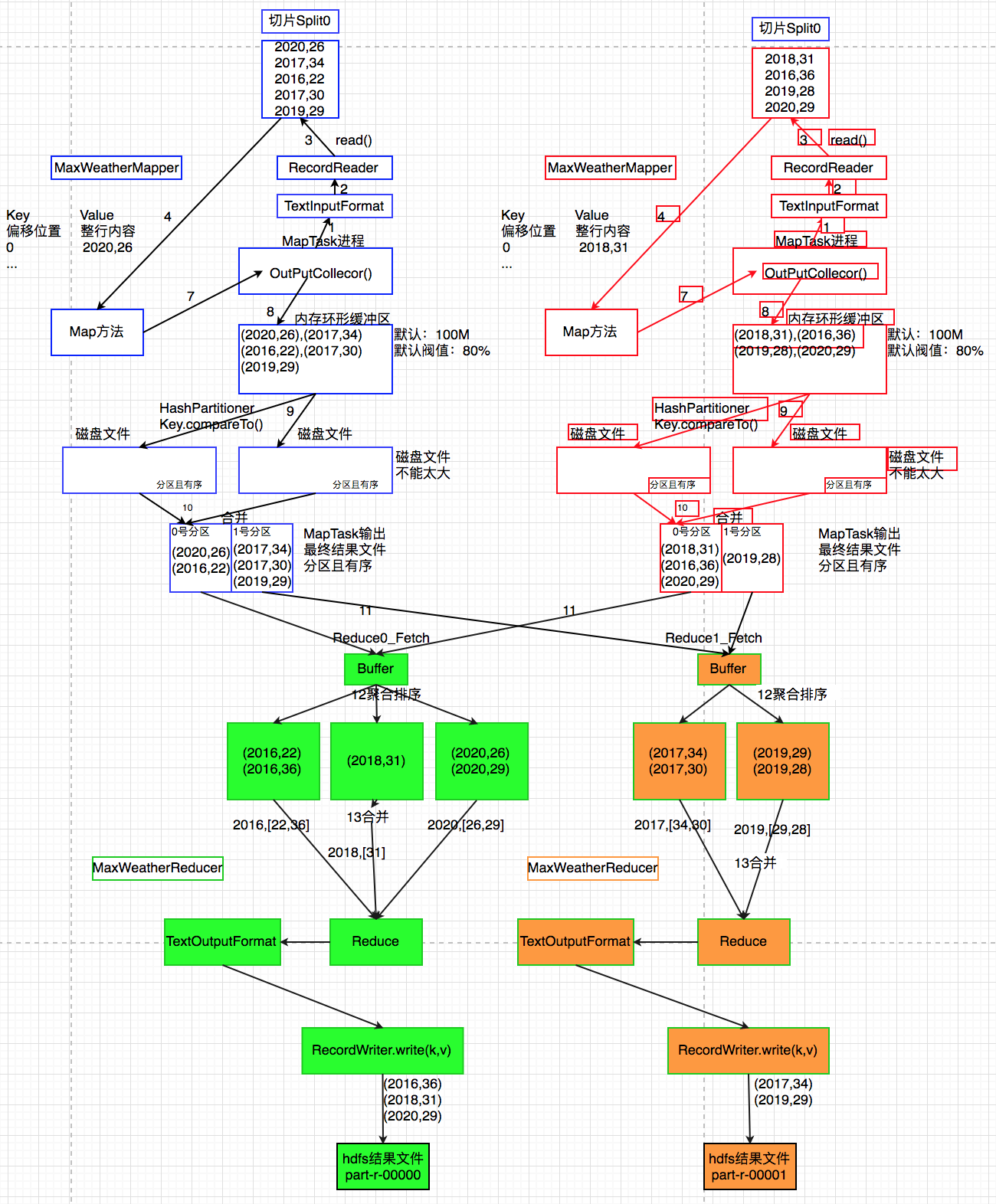
5.代码实现如下:
package com.briup.MR;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class MaxWeather
extends Configured implements Tool {
static class MaxWeatherMapper
extends Mapper<LongWritable, Text, IntWritable,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] str=value.toString().split(",");
context.write(new IntWritable(Integer.parseInt(str[0])),
new IntWritable(Integer.parseInt(str[1])));
}
}
static class MaxWeatherReducer
extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int max=0;
for(IntWritable iw:values){
if(iw.get()>max){
max=iw.get();
}
}
context.write(key,new IntWritable(max));
}
}
public int run(String[] args) throws Exception {
//构建配置对象,读取hadoop的配置文件,如hdfs-site.xml、yarn-site.xml、
//core-site.xml、mapred-site.xml等
Configuration conf=getConf();
//指定需要处理数据的hdfs文件路径
String input=conf.get("input");
//指定Mapreduce程序执行结果存放的路径
String output=conf.get("output");
//构建作业程序
Job job=Job.getInstance(conf);
//指定作业运行的类
job.setJarByClass(this.getClass());
//指定提交作业的名字
job.setJobName("MaxWeather");
//指定Mapper程序是哪个类
job.setMapperClass(MaxWeatherMapper.class);
//指定Mapper输出的键类型
job.setMapOutputKeyClass(IntWritable.class);
//指定Mapper输出的值的类型
job.setMapOutputValueClass(IntWritable.class);
//设置Reduce的个数
job.setNumReduceTasks(2);
//指定Reduce程序是哪个类
job.setReducerClass(MaxWeatherReducer.class);
//指定Reduce程序输出的键类型
job.setOutputKeyClass(IntWritable.class);
//指定Reduce程序输出值的类型
job.setOutputValueClass(IntWritable.class);
//指定文件和Mapper之间对接的处理器,处理器负责将文件每行内容按照特定规则转化为键值
//键值对交给Mapper
//TextInputFormat读取每一行数据起始位置为偏移位置,整行内容为值
job.setInputFormatClass(TextInputFormat.class);
//指定Reduce输出结果和结果存储文件的处理器,处理器负责将Reduce输出键值对按照特定规则写入结果文件
job.setOutputFormatClass(TextOutputFormat.class);
//负责读数据的处理器绑定读取文件路径
TextInputFormat.addInputPath(job,new Path(input));
//负责写数据的处理器绑定存储结果文件路径
TextOutputFormat.setOutputPath(job,new Path(output));
//提交作业给集群,true表示集群执行程序结束提交窗口命令行
return job.waitForCompletion(true)?0:-1;
}
public static void main(String[] args) throws Exception {
System.exit(
new ToolRunner().run(
new MaxWeather(),args));
}
}
将编写的程序所在工程打成jar包
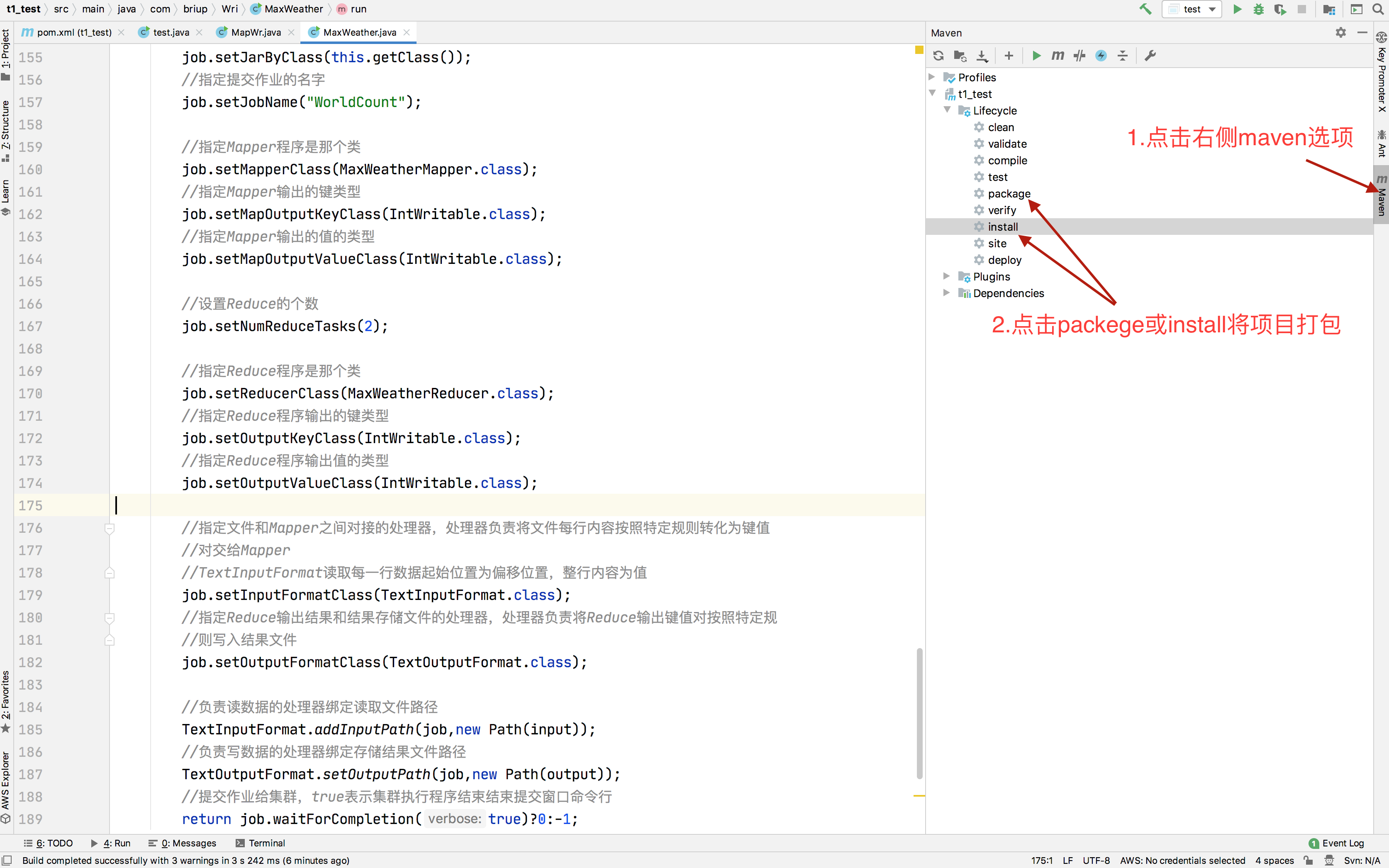
将项目jar包所在的计算机拷贝到hadoop集群计算机中
scp t1_test-1.0-SNAPSHOT.jar hdfs@192.168.43.8:~提交程序给集群执行
yarn jar t1_test-1.0-SNAPSHOT.jar com.briup.MR.MaxWeather -D input=/user/hdfs/wea -D output=/user/hdfs/weather_result查看计算结果
hdfs dfs -cat /user/hdfs/weather_result/part-r-00000
hdfs dfs -cat /user/hdfs/weather_result/part-r-00001Yarn命令补充列出所有的Application正在运行的任务:
yarn app -list
关闭yarn集群中正在执行的任务
yarn app -kill application_1692000495174_0002


 苏ICP备2020067766号-2
苏ICP备2020067766号-2