6.6 MR性能调优
完成条件
Mapper阶段可选配置

自定义分区,减少数据倾斜,具体实施自定义类,继承Partitioner,重写getPartition方法
减少溢写的次数
| 配置属性 | 描述 |
|---|---|
| mapreduce.task.io.sort.mb | 环形缓冲区大小,默认100M,可以适当提高,如200M |
| mapreduce.map.sort.spill.percent | 环形缓冲区溢出阀值,默认80%,可以适当提高,如90% |
增加每次Merge合并的次数(分区1归并)
| 配置属性 | 描述 |
|---|---|
| mapreduce.task.io.sort.factor | 默认一次最多合并10个文件,可以适当提高,如20 |
在不影响业务结果的前提条件下可以采用Combiner
减少磁盘io,可以采用压缩的方式对写入磁盘的数据压缩(压缩格式常用Snappy或LZO)
conf.setBoolean("mapreduce.map.output.compress",true);
conf.setClass("mapreduce.map.output.compress.codec",SnappyCodec.class,CompressionCodec.class);内存设置
配置属性 描述 mapreduce.map.memory.mb MapTask默认内存上限1G,可以根据128M数据对应1G内存原则适当提高内存 mapreduce.mao.java.opts 控制MapTask堆区内存大小,默认1G,如果MapTask内存提升,建议是其的0.75倍或相等,但是不能大于MapTask内存
当前程序如果是计算密集型,可以通过提高CPU核数提高计算效率
配置属性 描述 mapreduce.map.cpu.vcores 默认MapTask的CPU核数为1,可以适当增加CPU核数
异常重试
配置属性 描述 mapreduce.map.maxattempts 每个MapTask最大重试次数,默认4次,一旦重试次数超过该值,则认为MapTask任务失败,根据计算机性能可以适当调整
Reduce阶段可选配置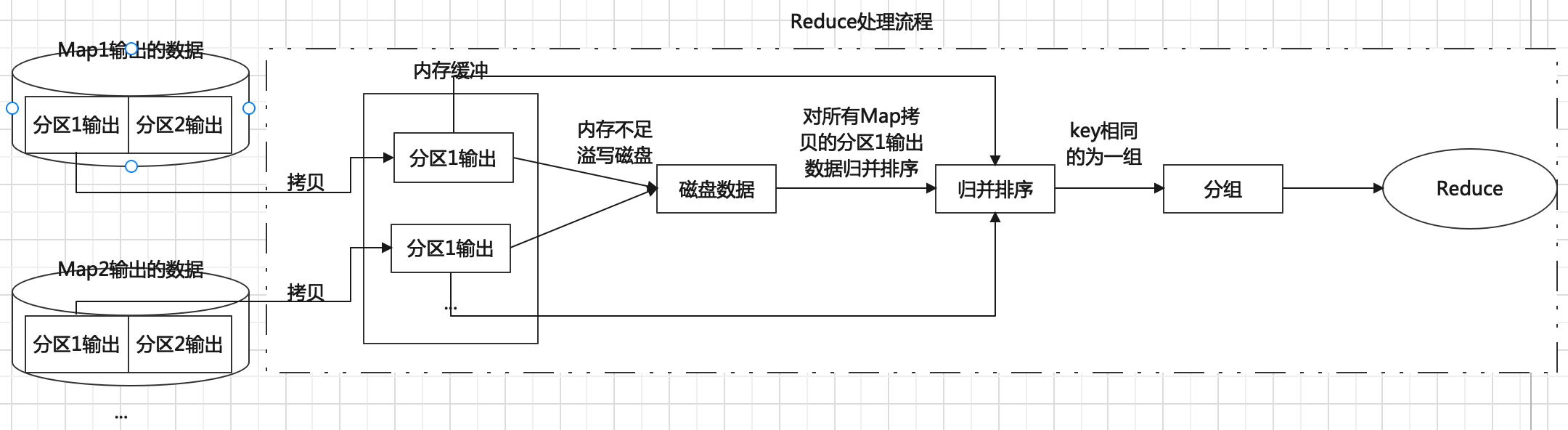
| 配置属性 | 描述 |
|---|---|
| mapreduce.reduce.shuffle.parallelcopies | 每个Reduce去Map中拉取数据的并行度,默认值是5,可以适当提高,如10 |
| mapreduce.reduce.shuffle.input.buffer.percent | Buffer缓存占Reduce可用内存的比列,默认是0.7,可以适当提高,如0.8 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的数据达到多少比列开始写入磁盘,默认0.66,可以适当提高,如0.75 |
| mapreduce.reduce.memory.mb | ReduceTask内存,默认上限1G,根据128M数据对应1G内存原则,可以适当提高 |
| mapreduce.reduce.java.opts | 控制ReduceTask堆内存大小,默认1G,如果ReduceTask内存提升,建议是其的0.75倍或相等,但是不能大于ReduceTask内存 |
| mapreduce.reduce.cpu.vcores | ReduceTask的CPU核数,默认为1,如果Reduce中程序是计算密集型,可以适当增加CPU核数,从而提高计算性能 |
| mapreduce.reduce.maxattempts | ReduceTask最大重试次数,默认为4,一旦重试次数超过该值,则认为ReduceTask任务失败,根据计算机性能可以适当调整 |
| mapreduce.job.reduce.showstart.completedmaps | 当MapTask完成的比列到达指定的值ReduceTask开始申请资源,默认0.05 |
| mapreduce.task.timeout | 一个Task在一定时间没有数据进入(即不会读取新数据),也没有输出数据,则认为该Task处于Block状态,换言之卡住了,也许永久卡住,为了防止该情况的出现,可以强制设置一个超时时间(单位毫秒),默认600000(10分钟),如果机器性能不佳或程序对每条数据处理时间很长,建议将该参数调大 |
最后修改: 2023年12月28日 星期四 17:21


 苏ICP备2020067766号-2
苏ICP备2020067766号-2