2.1 集群简介
完成条件
Hadoop 集群具体来说包含两个集群:Hdfs 集群和 Yarn 集群,两者逻辑上分离,但物理上常在一起。
HDFS 集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode。
YARN 集群负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager。
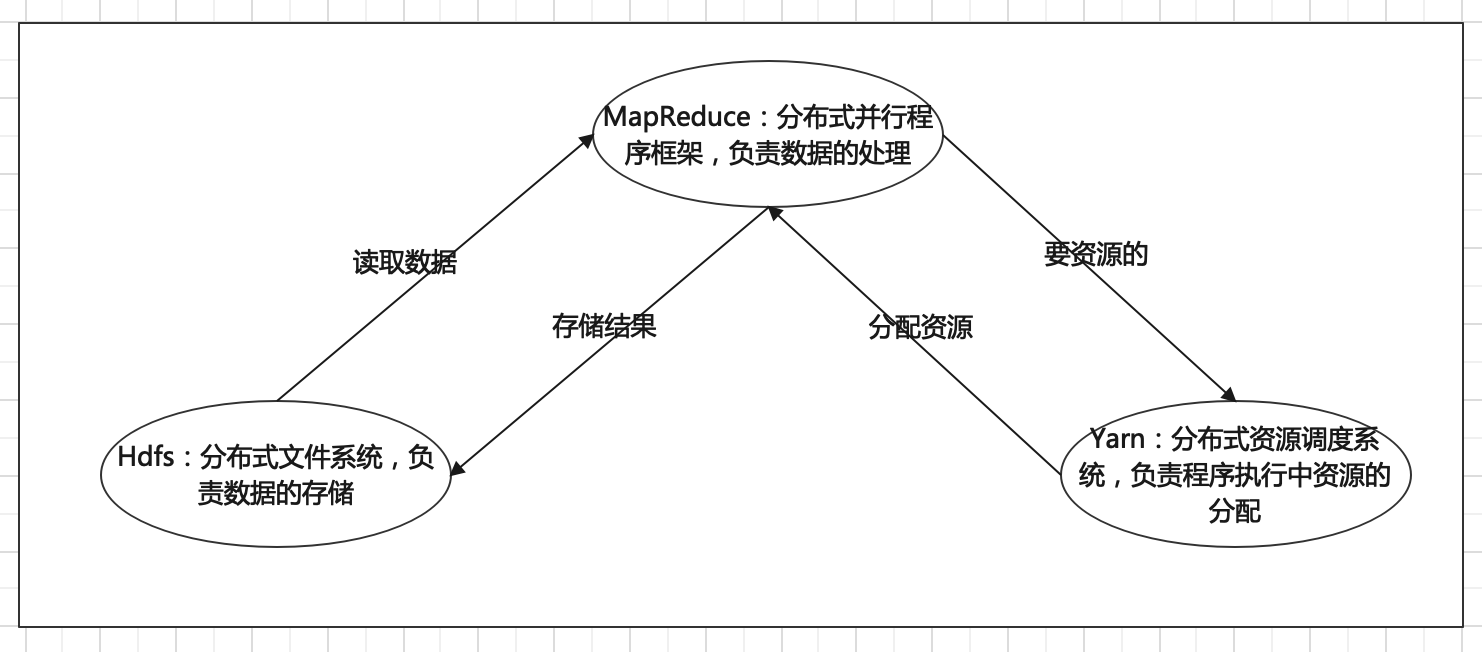
Mapreduce 是什么呢?
它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS 集群上,并且受到YARN集群的资源调度管理。
最后修改: 2023年12月27日 星期三 15:38


 苏ICP备2020067766号-2
苏ICP备2020067766号-2