3.1 HDFS概述
在现代的企业环境中,海量数据超过单台物理计算机的存储能力,分布式文件系统应运而生,对数据分区存储于若十物理主机,管理网络中跨多台计算机存储的文件系统。
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统, HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.

传统的文件存储系统?
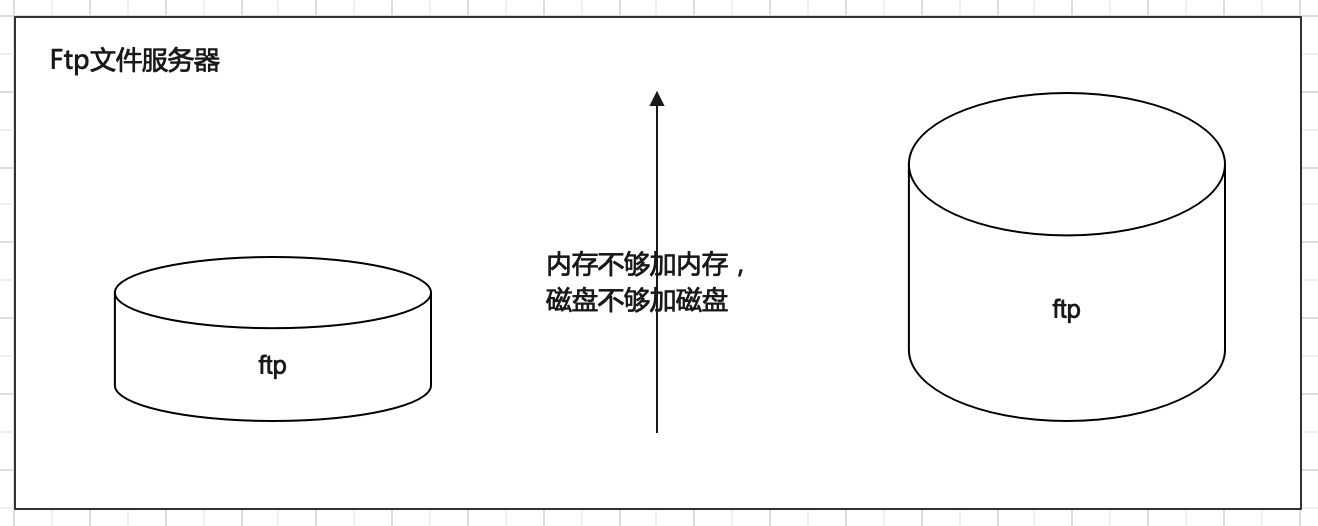
应对文件存储服务,传统做法是在服务器上部署文件服务比如FTP。但是随着数据变多,会遇到存储瓶颈。此时,本能的操作反应是:内存不够加内存,磁盘不够加磁盘—单机纵向扩展。但是单机能够扩展的内存磁盘是有上限的,不能无限制下去。
分布式存储方式?
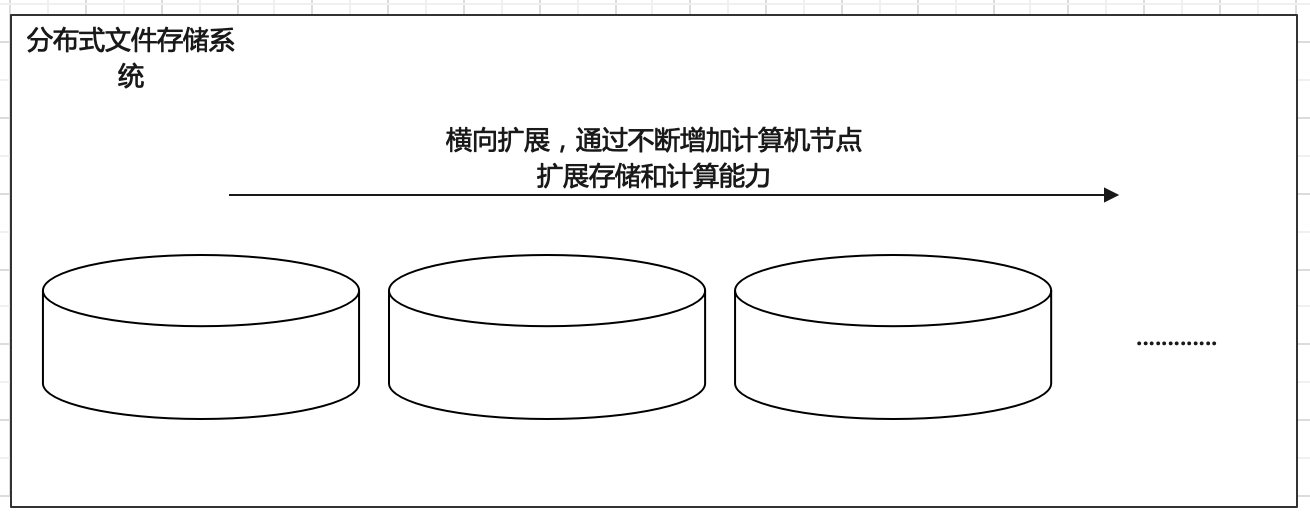
纵向扩展有上限,自然想到横向扩展。所谓横向指的是采用多台机器存储,一台不够就多台一起存储,不够就加机器。理论上,可以横向无限制下去。因此海量数据如何存储问题解决方式就是采用多台机器存储—即分布式存储。
如何解决数据查询便捷问题?
当文件被分布式存储在多台机器之后,后续获取文件的时候如何能快速找到文件位于哪台机器呢。一台一台查询过来也不靠谱。因此可以借助于元数据记录来解决这个问题。把文件和其存储的机器的位置信息记录下来,类似于图书馆查阅图书系统,这样就可以快速定位文件存储在哪一台机器上。
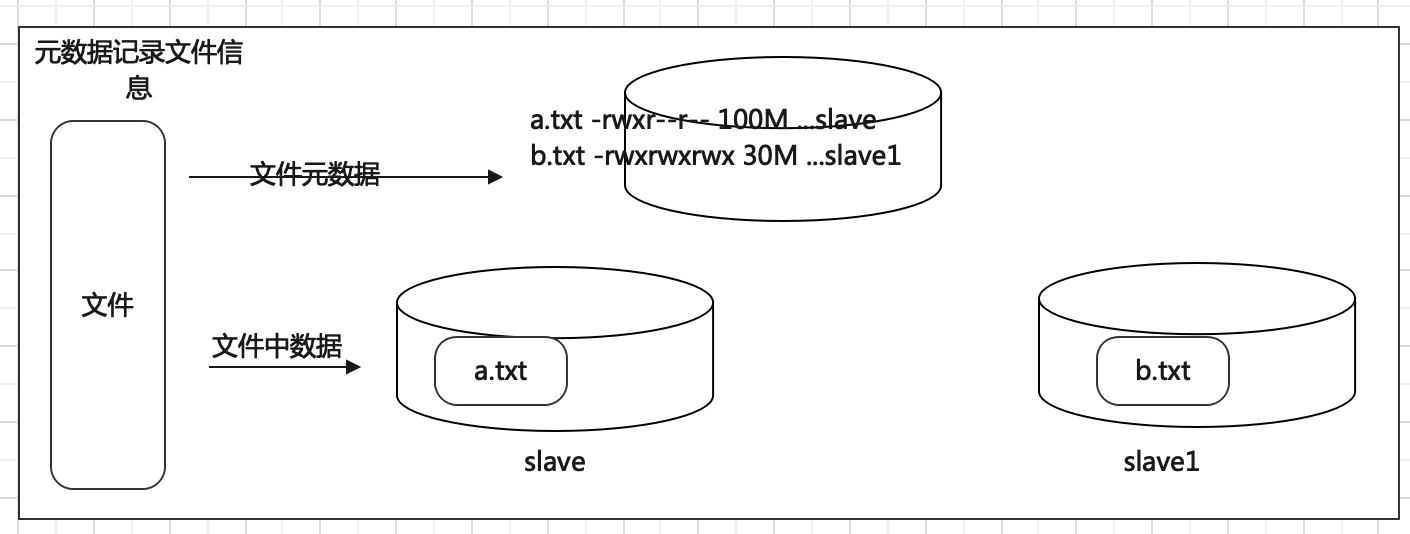
在 HDFS 中,元数据具有两种类型:
1、文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
2、文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
如何解决大文件传输效率慢问题?
大数据使用场景下,GB、TP级别的大文件是常见的。当单个文件过大的时候,如何提高传输效率?通常的做法是分块存储:把大文件拆分成若干个小块(block 简写blk),分别存储在不同机器上,并行操作提高效率。
此外分块存储还可以解决数据存储负载均衡问题。此时元数据记录信息也应该更加详细:文件分了几块,分别位于哪些机器上。
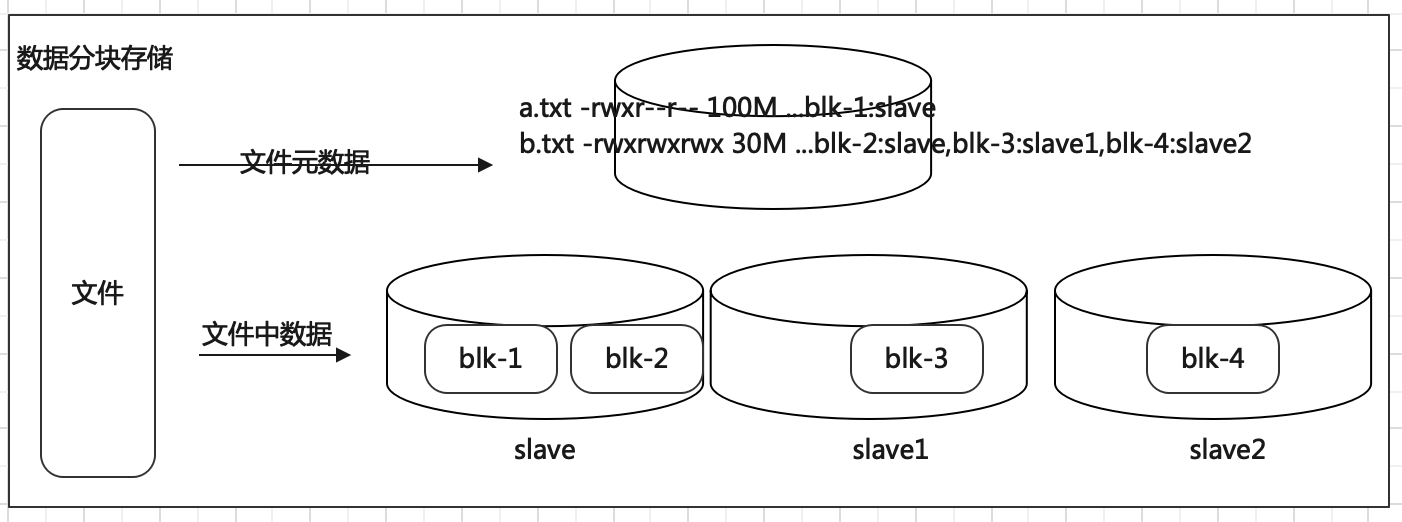
HDFS中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于 hdfs-default.xml 中:dfs.blocksize。默认大小是 128M(134217728)
如何解决数据丢失问题?
机器、磁盘等硬件出现故障是难以避免的事情,如何保证数据存储的安全性。如果某台机器故障,数据块丢失,对于文件来说整体就是不完整的。冗余存储是个不错的选择。采用副本机制。副本越多,数据越安全,当然冗余也会越多。通过“不要把鸡蛋放在一个篮子里”的思想,可以把数据丢失的风险分散到各个机器上。
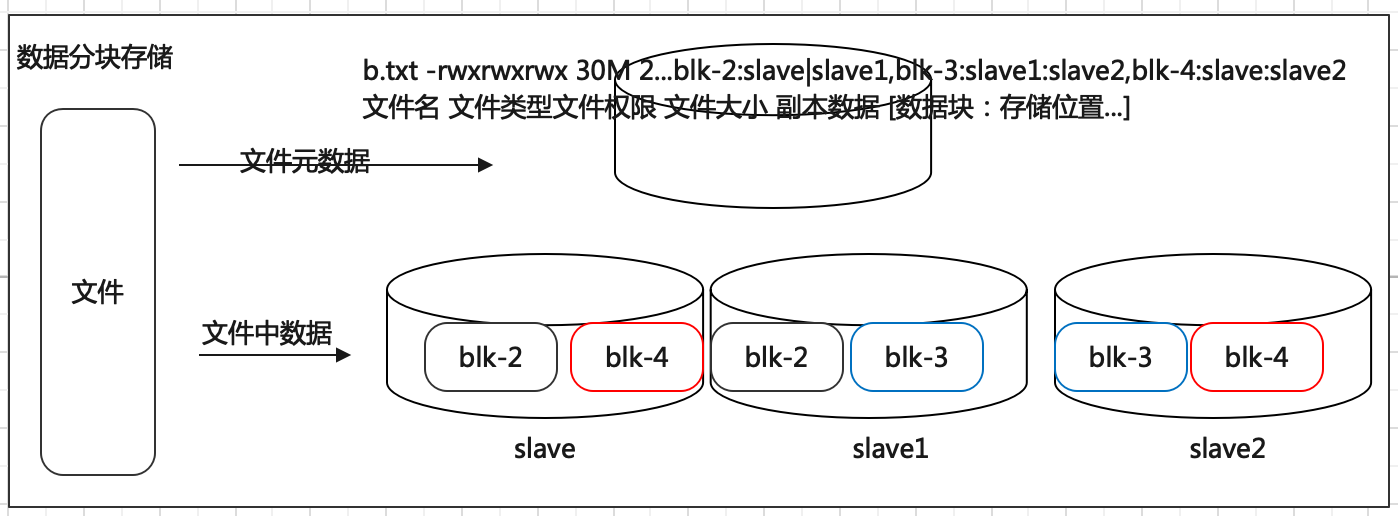
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认 dfs.replication 的值是 3,也就是会额外再复制2份,连同本身总共 3 份副本。
如何解决用户查询视角统一问题?
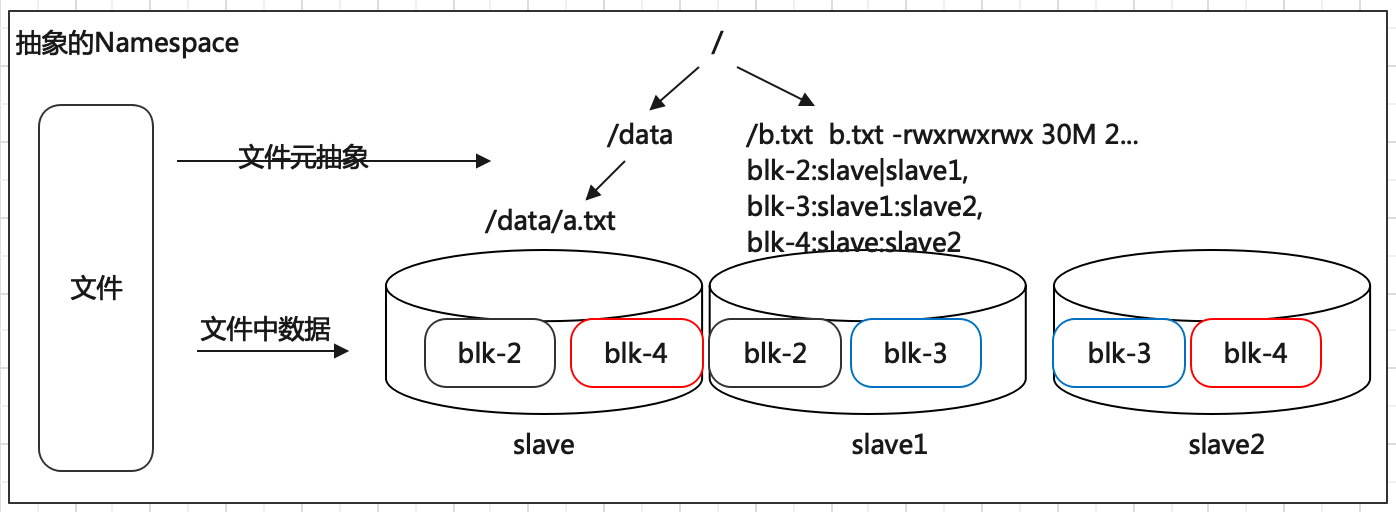
随着存储的进行,数据文件越来越多,与之对应元数据信息也越来越多,如何让用户视觉层面感觉不到元数据的凌乱,同时也与传统的文件系统操作体验保持一致?传统的文件系统拥有所谓的目录树结构,带有层次感的namespace(命名空间),因此可以把分布式文件系统的元数据记录这一块也抽象成统一的目录树结构。


 苏ICP备2020067766号-2
苏ICP备2020067766号-2