6.3 集群压测
在企业中非常关心每天从Java后台拉取过来的数据,需要多久能上传到集群?消费者关心多久能从HDFS上拉取需要的数据?为了搞清楚HDFS的读写性能,生产环境上非常需要对集群进行压测。
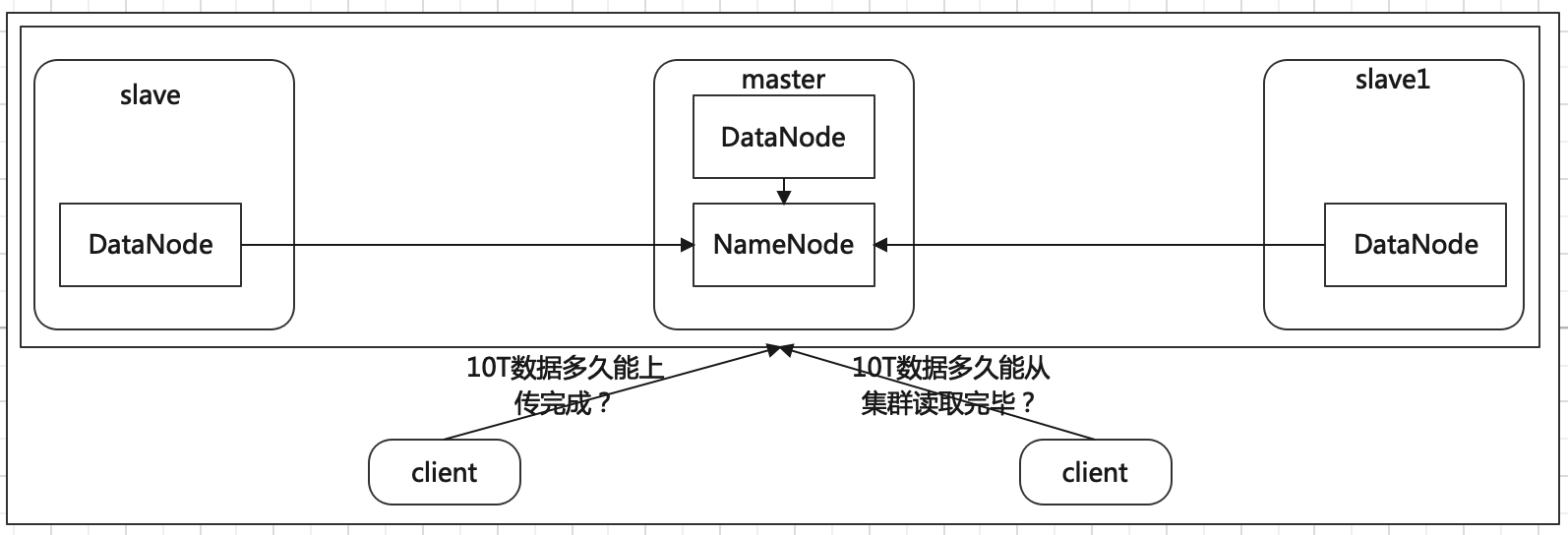
HDFS的读写性能主要受网络和磁盘影响比较大。为了方便测试,将master、slave、slave1虚拟机网络都设置为100mbps。点击虚拟机点击右键->设置->网络适配器->高级选项
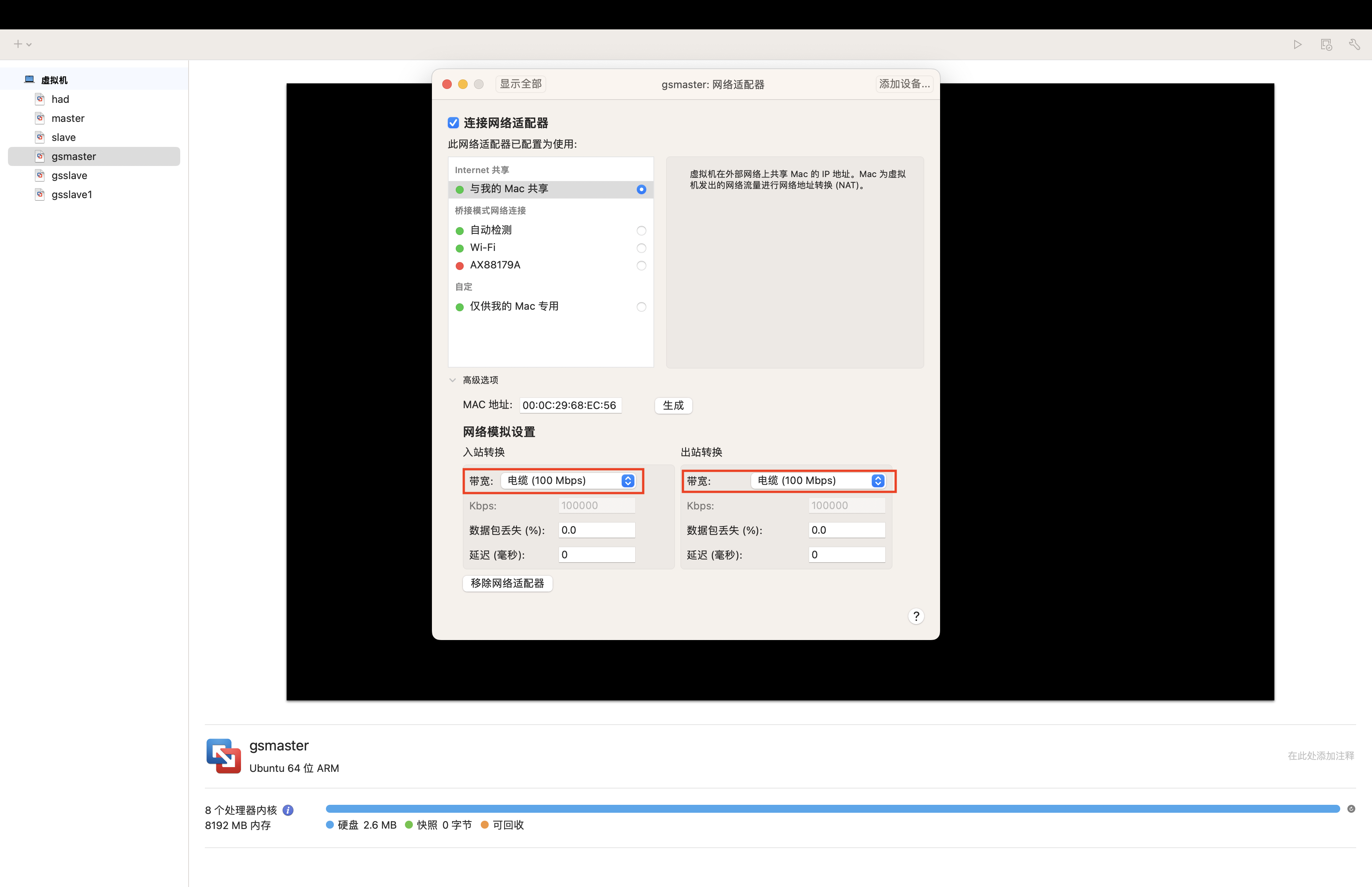
100Mbps单位是bit;10M/s单位是byte ; 1byte=8bit,100Mbps/8=12.5M/s
3台服务器的带宽12.5+12.5+12.5=37.5M/s
Hdfs 写性能
向HDFS集群写10个128M的文件
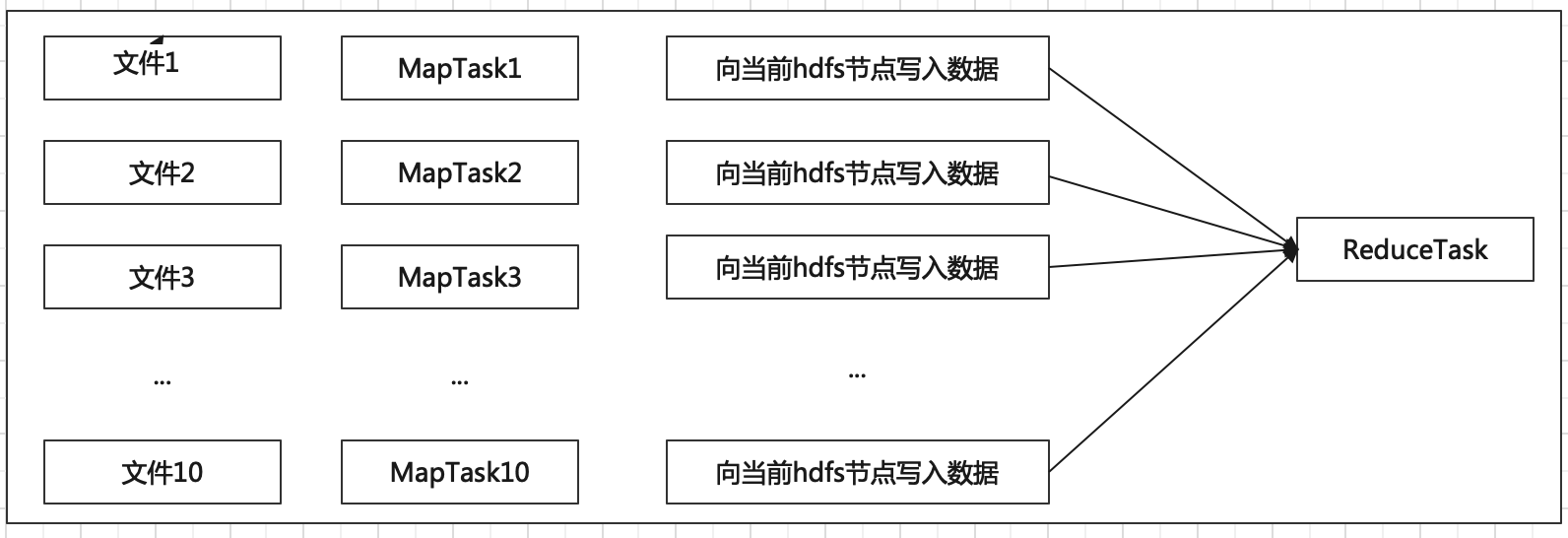
执行写入测试命令:
程序执行结果
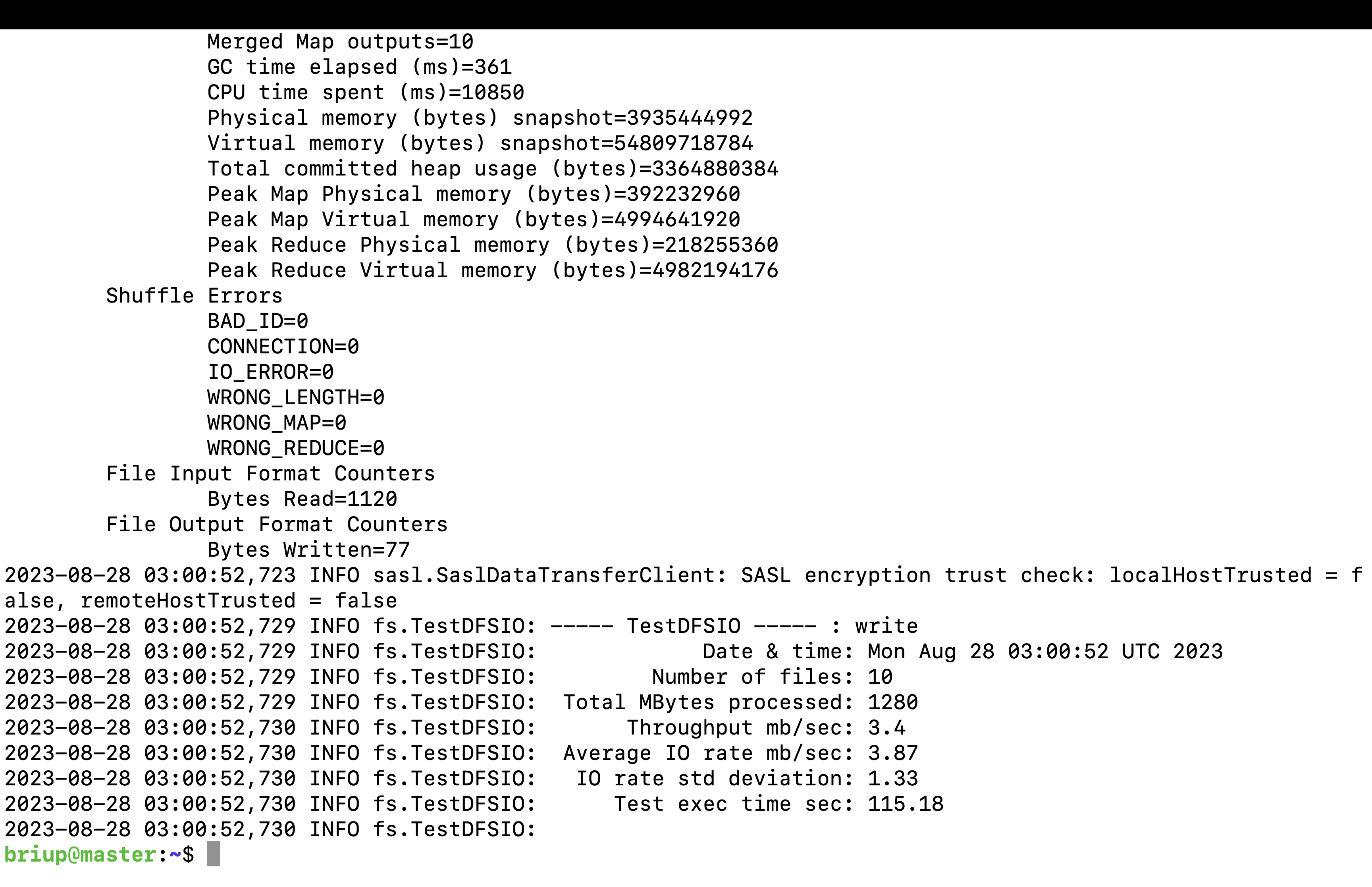
Number of files:生成mapTask数量,一般是集群中(CPU核数-1),我们测试虚拟机就按照实际的物理内存-1分配即可
Total MBytes processed:单个map处理的文件大小
Throughput mb/sec:单个mapTak的吞吐量,处理的总文件大小/每一个mapTask写数据的时间累加,集群整体吞吐量:生成mapTask数量单个mapTak的吞吐量,集群写入总的吞吐量3.4``10=34M/s
Average IO rate mb/sec:平均mapTak的吞吐量,每个mapTask处理文件大小/每一个mapTask写数据的时间全部相加除以task数量
IO rate std deviation:方差、反映各个mapTask处理的差值,越小越均衡
执行测试如果报错,可以在yarn-site.xml中设置虚拟内存检测为false
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>如做修改需要分发配置整个集群并重启Yarn集群
总结:如果实测速度远远小于网络,并且实测速度不能满足工作需求,可以考虑采用固态硬盘或者增加磁盘个数。测试HDFS读性能
1.执行命令读取HDFS集群10个128M的文件:
yarn jar software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
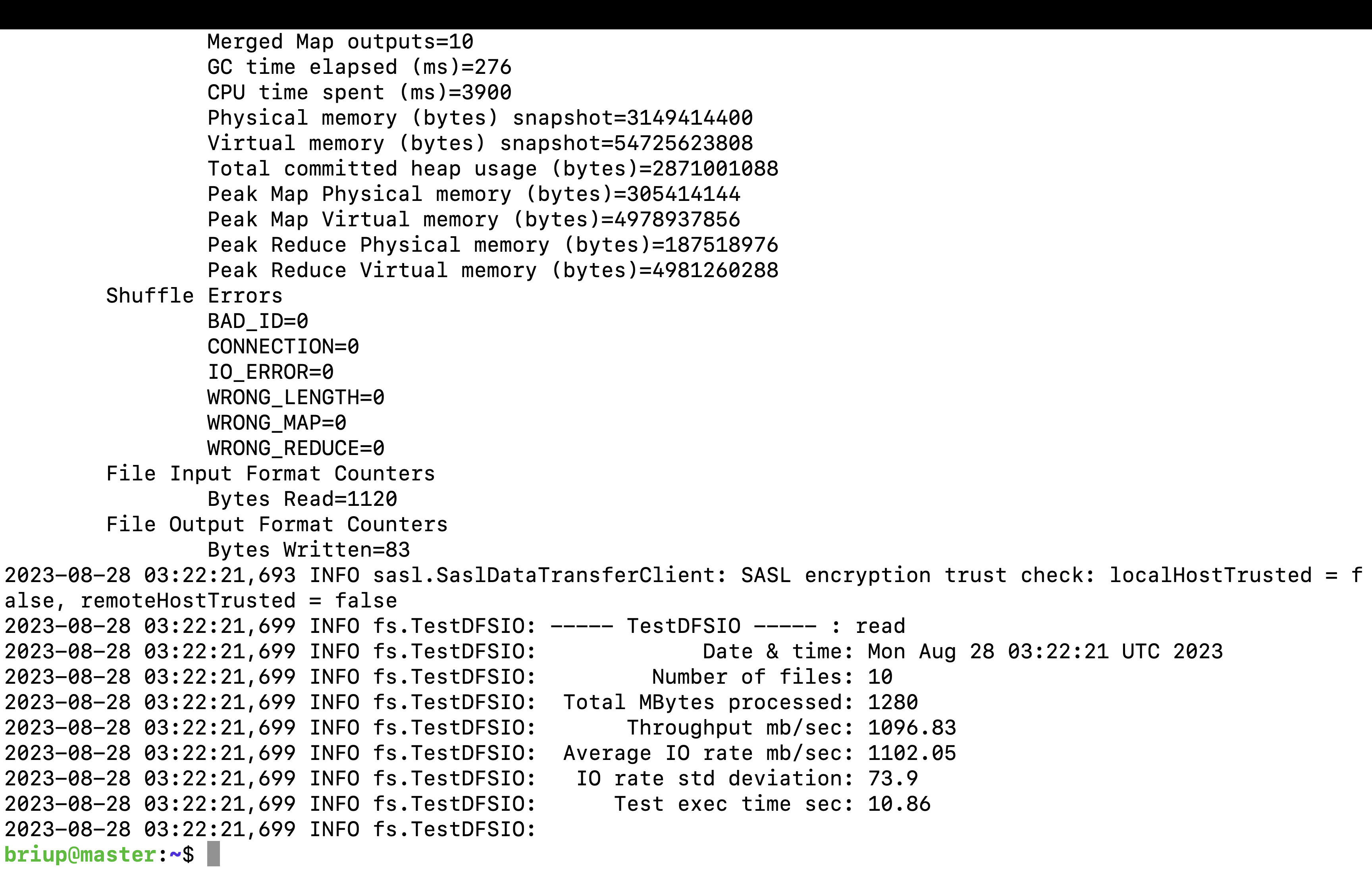
为什么读取文件速度大于网络带宽?
由于目前只有三台服务器,且有三个副本,数据读取就近原则,相当于都是读取的本地磁盘数据,没有走网络。
删除测试数据
yarn jar software/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean

 苏ICP备2020067766号-2
苏ICP备2020067766号-2